)
In this article we'll develop a simple IR application: retrieving appropriate documents from a set of online manuals. Since our knowledge about the user's "information need" is inevitably complete and the collection of documents is limited, the retrieval is doomed to some fuzziness.( IR people tend to avoid the term "database" in favor of the term "collections". In recent years database people have hijacked that term too. Also, the objects in the collections are usually referred to as "documents" regardless of their nature. And since the term "fuzzy" has been commandeered by the fuzzy set theoreticians, you should avoid it in the context of IR. There are people who claim that you can use the fuzzy set theory for IR. Don’t believe them!)
The diagram below depicts a generic IR system. On the left, knowledge in the real world is incorporated into some digital document, which in turn is transformed into some representation usable by the system. On the right, a user's need is expressed in a query language that is also transformed into an internal representation. How the representations are compared is defined by the retrieval model which is just a stuffy phrase for a function meant to compute the relevance of the document with respect to the query. As stated above the system cannot decide about the relevance itself. At best, it can guess the probability that a user will accept the document as a valid answer to his query.
The unavoidable loss during the transformations is called "Uncertainty" on the document side and "Vagueness" on the query side. In fact, it's a definition for IR:
Information Retrieval systems deal with Uncertainty and Vagueness.
The attributes of documents expressible with queries can be grouped into three categories: logical, syntactic, and semantic. We're familiar with logical attributes from conventional database systems; 'title' and 'author' are examples. Unlike most database systems, good information retrieval systems provide some means of dealing with uncertainty in the input, such as typographic errors. Syntactic attributes store layout information, for example "Find me that business letter with this blue logo on the top right corner." Finally, semantic attributes encapsulate the system's understanding of the document content.
Now that we've got the big picture, let's consider a simple application. Most questions lobbed at system administrators can be answered with two words. The first is man and the second regrettably varies. Wouldn't it be nice if the user could enter his query as "How do I ..." to our new system and be referred automatically to the set of relevant manual pages?
This application will let us focus on the semantic attributes of manual pages. Manuals mostly look alike, so the syntactic layout information is of little use. We'll also ignore the logical attributes, although some of them (for instance, the size and date of the files) could be helpful.
Now we have to decide what retrieval model to use. We resort to a simple yet powerful approach: Salton's Vector Space Model [Salton], which represents queries and documents as vectors of real numbers, each dimension representing a term in the dictionary. The value of the nth entry of the vector is called the "weight" of word n with respect to the document. Comparing the query and a document vector (say, by computing the scalar product) yields the probability of relevance of the document with respect to the query.( Salton used several other similarity functions such as cosine and dice that require normalization of the vector lengths.) This value is often called the retrieval status value (RSV) to stress that it is not an estimate of the probability but rather some transformation of it.
For the query vector we simply set the corresponding vector element to 1 if the word is present in the query and 0 otherwise. For the document vectors we do something slightly more elaborate. Let's assume that the query word under consideration occurs in n of all N documents. It occurs tf times in the current document, and the most frequent word in the document occurs maxtf times. Given that, we define the weight for a word i as:
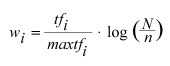
We see that the more frequent the word, the higher its weight. Since longer documents tend to have more occurrences of any given word, the maxtf compensates by decreasing the weight accordingly. The logarithm ensures that words occurring in many documents (e.g. "print") yield a lower weight than others.
Let's recall what we need. For each document we need to know how often its most frequent word occurs. We also need a headline: some information to display describing the document. For each word in the query, we need the list of documents containing the word along with the frequency of the word in the documents. To save disk space, we won't store the filenames, but will number the documents instead. If we want to be able to incrementally update our index we also need the reverse mapping to check if a manual is already indexed.
To make our code usable by both the indexer and the query interface, we encapsulate it in a module called Man::Index. That, and all the other code in this article, is available from the TPJ web site. The module's constructor, new(), takes two named arguments: A directory were the index files are stored and a flag indicating whether the index files should be opened for updating or just for reading.
sub new {
my $type = shift;
my %parm = @_;
my $self = {};
my $index = $parm{'index'}
|| croak "No 'index' argument given\n";
my $rw = $parm{rw};
my $flags = ($rw) ? O_RDWR : O_RDONLY;
unless (-d $index) {
if ($rw) {
mkpath($index,1,0755)
|| croak "Could not mkpath '$index': $!\n";
$flags |= O_CREAT;
} else {
croak "No index directory '$index': $!\n";
}
}
tie %{$self->{documents}}, 'AnyDBM_File',
"$index/documents", $flags, 0644
or die "Could not tie '$index/documents': $!\n";
tie %{$self->{doc_entry}}, 'AnyDBM_File',
"$index/doc_entry", $flags, 0644
or die "Could not tie '$index/doc_entry': $!\n";
tie %{$self->{doc_no}}, 'AnyDBM_File',
"$index/doc_no", $flags, 0644
or die "Could not tie '$index/doc_no': $!\n";
bless $self, $type;
}
The first hash, %{self->{documents}}, maps the dictionary words to a list of document numbers and frequencies. This index is often called an inverted file because it represents the "inverse" of the documents which can themselves be thought of as mapping document numbers to words. For convenience we implement a documents() method that, depending on the number of arguments, either returns the list of documents for a word, or appends to that list:
sub documents {
my $self = shift;
my $word = shift;
if (@_) {
# @_ = ($document_number, $frequency)
$self->{documents}->{$word} .= pack 'ww', @_;
} else {
unpack 'w*', $self->{documents}->{$word};
}
}
We use a new pack() format unavailable in all but the most recent versions of Perl: w, which we use to store our word frequencies as compressed integers to save space. Anyway, to look up the word "Information" we use:
%frequency = $self->documents('information');
@document_numbers = keys %frequency;
The second hash, %{self->{doc_entry}}, maps document numbers to the document related data: maximum frequency, path and headline. We use the special entry _ _maximum_document_number_ _ to store the number of documents in the index. The %{$self->{doc_no}} hash is used for the inverse mapping: path to document number.
sub make_document_entry {
my ($self, $path, $maxtf, $headline) = @_;
my $docno =
++$self->{doc_entry}->{_ _maximum_document_number_ _};
$self->{doc_entry}->{$docno} = pack('S',$maxtf) .
join($;, $path, $headline);
$self->{doc_no}->{$path} = $docno;
return $docno;
}
The methods maxtf(), path() and headline() (not shown here) look up the values for a given document number.
Using these methods, we can implement another method for adding a document to our index. It takes a filename as its argument after the obligatory first argument containing the object itself:
sub add_document {
my ($self, $file) = @_;
# check for symbolic links or already indexed files
return unless $self->is_reasonable($file);
# handle compression
my $fh = $self->open_file($file) || return;
my ($headline, $maxtf, %frequency, $line);
while (defined($line = <$fh>)) {
if (!$headline and $line =~ /\.S[Hh] NAME/) {
$headline = $self->get_headline($fh);
}
for my $term ($self->words($line)) {
$frequency{$term}++;
$maxtf = $frequency{$term}
if $frequency{$term} > $maxtf;
}
}
$headline ||= $path;
my $doc_number =
$self->make_document_entry($path,$maxtf,$headline);
while (my($term, $freq) = each %frequency) {
$self->documents($term, $doc_number, $freq);
}
return ($doc_number, $headline);
}
The first while loop iterates over the lines of the file. After checking for the headline, the words() method splits each line into words, counts the occurrences, and computes the maximum frequency. Then a new document entry is generated and the second while loop appends the ($doc_number, $freq) pair to the appropriate inverted lists. This is often called "posting." The method returns the document number and its headline so that the caller can print something meaningful while we're waiting for it to finish.
Although the three helper functions is_reasonable(), open_file(), and get_headline() are conceptually simple, the method words() is more exciting since it will greatly influence the retrieval quality and the index size. A minimal implementation might look like this:
sub words {
my ($self, $text) = @_;
for ($text) {
s/\\f.//g; # \fB and the like
tr/A-Za-z0-9/ /cs;
}
split ' ', $text;
}
Here the \f macros (which control font selection in troff-encoded man pages) are removed, all non-alphanumeric characters are replaced by spaces, and the result is split on spaces. Unfortunately, this simple implementation treats the words "computer" and "computers" as different words. Searching for one of them will miss the other. Since man pages are generally in English, we can use the Text::English module from the CPAN to map the words to their stems. This solves the problem and reduce the index size at the same time. Furthermore, since roughly half of normal text consists of two hundred so-called stopwords like 'the' and 'an', we could save about the same fraction of index space by removing them. This can be done simply by checking all the words for existence in a hash of stopwords.
We're now ready to write a make_index script. Error handling and option parsing have been removed for clarity:
my $index = new Man::Index index => '/tmp/man', rw => 1;
for my $dir (@mandir) {
opendir BASE, $dir;
for my $sub (grep -d "$dir/$_", grep /^man/,readdir BASE) {
my $path = "$dir/$sub";
opendir SUBDIR, $path;
for my $page (grep -f "$path/$_", readdir SUBDIR) {
if (my ($number, $headline) =
$index->add_document("$path/$page")) {
printf("%4d %s\n", $number, $headline);
}
}
}
closedir BASE;
}
This indexer takes a long time when given a large collection of man pages. So while we're waiting for it to finish, we can implement the search() method:
sub search {
my $self = shift;
$self->search_raw($self->words(shift));
}
sub search_raw { # assumes query words are normalized
my $self = shift;
my (%score);
WORD:
for my $term (@_) {
if (my %post = $self->documents($term)) {
#document frequency
my $n = scalar keys %post;
my $idf = log($self->num_documents/$n);
# term occurs in every document
next WORD if $idf == 0;
for my $doc_no (keys %post) {
my $maxtf = $self->maxtf($doc_no);
$score{$doc_no} += $post{$doc_no} /
$maxtf * $idf;
}
}
}
\%score;
}
search() just splits the query string into words and calls upon search_raw() to do the real work. In search_raw() we loop over the words and look up the posting list for each of them. The total number of documents (stored in _ _maximum_document_number_ _ and assessed via the num_documents() method) is divided by the number of documents in the list - our n above. The logarithm of the result is the second part of our formula for the document weight. The for loop computes the first part for each document; the frequency of each word is divided by the maximum word frequency. The product of both parts is then added to the current score for the document, which implements the dot product of the document vector and the query vector. The method returns a reference to a hash were the keys are the document numbers and the values are their scores.
A minimal search script using our system might look like this:
my $x = new Man::Index index => '/tmp/man';
my $score = $x->search(join ' ', @ARGV);
my $display = 10;
for my $doc_no (sort {$score->{$b} <=> $score=>{$a}}
keys %$score) {
printf "%5.3f %s\n\t%s", $score->{$doc_no},
$x->headline($doc_no),
$x->path($doc_no);
last unless --$display;
}
Before we can sell this system, we need an interface that lets users enter queries and inspect the results. The system on the TPJ Web server contains a simple shell based interface. In addition to its retrieval capabilities, it also collects relevance judgments from the users. They can mark individual answers as relevant or irrelevant to their current query, and we can make use of this data with the "Binary Independence Retrieval Model" (BIR), discussed in [Robertson].
The BIR uses two pieces of information to determine the relevance of a document: whether a query word is present in the document (frequency is ignored; hence the "Binary"), and the relevance feedback from the user. We assume that the user has judged r documents relevant and i documents irrelevant. For a given word, we compute pk, the probability that it occurs in a relevant document, and qk, the probability that it occurs in an irrelevant document:
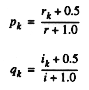
(The 0.5 and 1.0 ensure that we never divide by zero.) We then compute the weight for a document as sum over all query words.
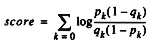
The mathematics is explained in [Robertson]. Our implementation assumes that %all indexes the document numbers of judged documents and %good indexes the document numbers of relevant documents.
my $good = scalar keys %good;
my $all = scalar keys %all;
my %score;
for my $word ($self->words($QUERY) {
my ($f, $r);
my %document = $INDEX->documents($word);
for my $docno (keys %all) {
# document contains the word
if ($document{$docno}) {
$f++;
$r++ if $good{$docno};
}
}
my $p = ($r+0.5) / ($good+1);
my $q = ($f-$r+0.5) / ($all-$good+1);
for my $docno (keys %document) {
$score{$docno} += log($p*(1-$q)/$q/(1-$p));
}
}
The iman script on the TPJ Web site contains this code; experiment! As a rule of thumb, the more words your query contains, the better your results will be. We are doing IR here - not mega- grep implementations like most Internet search engines. You will never be confronted with 20,000 hits in no particular or justifiable order. After providing feedback to the system, you can expect the relevant documents among the top ranked ones.
Wish this system had boolean operators or regular expressions? Don't! We built the system for novice users who might not be familiar with boolean logic or regular expression metacharacters. With our system they'll get an answer even if only one query word is present in only one man page in the entire collection. With boolean expressions, even if a user succeeds in entering syntactically correct queries, he'll often get no result at all. Some studies (see e.g. [Salton, Fox, and Wu]) have shown that boolean logic doesn't buy the casual user much.
We have presented a conceptual framework for information retrieval as well as a simple but useful implementation. Feel free to extend the system by adding other retrieval models or by modifying the current ones. Think about the advantages of splitting the manual into sections and paragraphs. What would the representation then look like? Or consider the possibilities for enhancing the user interface by replacing man -l with your own pager that highlights the query terms.
Never forget that information retrieval is not about testing logic formulas on large data sets but about providing humans with the information they need.
_ _END_ _
Robertson, S. and Sparck Jones, K. Relevance Weighting of Search Terms. Journal of the American Society for Information Science 27, pp. 129-146, 1976.
Salton, G., E. Fox, and H. Wu. Extended Boolean Information Retrieval. Communications of the ACM 26, pp. 1022-1036, 1983.
Salton, G. and McGill, M. J. Introduction to Modern Information Retrieval. McGraw-Hill, New York, 1983.
Popularity of computer languages, as measured by
number of Web pages on Yahoo:
| 1. Java and JavaScript | 562 |
| 2. C and C++ | 118 |
| 3. Perl | 108 |
| 4. Visual Basic | 59 |
| 5. Tcl/Tk | 51 |