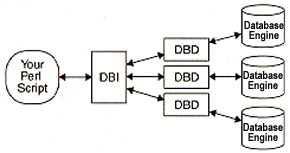
The architecture of DBI is an elegant one. We are channelled toward the solution by the very concept of the interface that we are trying to define. Furthermore, Perl, as usual, helps us along by providing powerful syntactic constructs and regular expressions that facilitate data processing on the scale required by large database applications.
The DBI interface is the term used to describe both the interface specification - the methods used to build your programs - and the software modules that make this possible. We'll first take a look at why you should be using DBI, and then describe the modular structure of DBI and its interaction with Perl. Finally, we'll show you some sample DBI code.
Database programming, as you will learn after you've programmed or administered a few different ones, is pretty much-of-a-muchness. Hence DBI. The fundamental processes involved in doing anything with a database are pretty similar right across the board: connecting to and disconnecting from the database, opening and closing cursors,( A cursor is a construct identifying a particular set of rows in a database.) and storing and retrieving data. The typical order in which this happens is:
Now, there are differences between each database engine, like datatypes of fields retrieved, precision, extra non-ANSI-compliant features and so on, but their basic operations are the same from system to system. DBI provides a unified layer so that people can write portable code while still allowing access to the non-standard features as well.
Once we've fetched some data from the database, what next? In general, DBI simply provides your data as scalar variables, which you can then manipulate as you would any other scalar.
Another feature is the ability to connect to more than one database simultaneously from within the same Perl program - even (dare we say it?) to databases from different vendors. You can connect to an Oracle and an mSQL and an Informix database at the same time. "What's the point in that?" I hear you cry. Well, say you have a corporate Oracle database, and you want to display some of its data on the Web. Oracle via CGI can be slow due to Oracle's internal login procedures, so you've decided to use mSQL as well.
Option number 1 is to write a program that runs SQL scripts and dumps the data to a flat file, perhaps comma-separated, which another program then reads and loads into the mSQL database. This is far too much like hard work.
Option number 2 is to write a single Perl script that connects simultaneously to both the Oracle and the mSQL databases, reads the data from Oracle, and puts it into mSQL transparently. Change Oracle to Informix and you won't need to alter a thing.
Think about that the next time you're writing two separate programs in C (a well-known excellent string and regular-expression-handling language) with different vendor precompilers on separate platforms. Then think on the paradise of cross-platform portability and cross-database connectivity. You know it makes sense.
DBI is a living organism and, coupled with Perl's current popularity for CGI scripting language and rapid development, will become a more important factor in decisions to use Perl as a "serious" programming language. Similarities have been drawn between DBI and ODBC( The Open Database Connectivity API. This defines an API for accessing databases based on X/Open and ISO standards. ODBC has taken several years to spread from being Microsoft specific to being shipped with Unix operating systems, such as Solaris 2.5. ODBC is more complex than DBI! ) that have led to questions of "Why do we need DBI?" DBI is simpler than ODBC. DBI will run immediately on more platforms than ODBC, except, rather perversely, the platform ODBC originally sprang from: Microsoft Windows. DBI is free. If this isn't enough to convince you, DBI will be extended in the future to allow you to use off-the-shelf ODBC drivers anyway.
Databases, be they Object Database Management Systems (ODBMS) or the more common Relational Database Management Systems (RDBMS) are engineered to store and retrieve data. That's their prime purpose. Unix was originally blessed with simple file-based "databases", namely the dbm system. dbm lets you store data in files, and retrieve that data quickly. However, it also has two notable drawbacks:
File Locking. The dbm systems did not allow particularly robust file locking capabilities, nor any capability for correcting problems arising from simultaneous writes.
Arbitrary Data Structures. The dbm systems only allows a single fixed data structure: key-value pairs. That value could be a complex object, such as a struct, but the key had to be unique. This was a large limitation on the usefulness of dbm systems.
However, the dbm systems still provide a useful function for users with simple datasets and limited resources, since they're fast, robust, and extremely well-tested. Perl modules to access dbm systems have now been integrated into the core Perl distribution via the AnyDBM_File module.
Perl 5 has a powerful mechanism to 'plug' external modules into the Perl interpreter. This mechanism is realized by actually compiling and linking the module into the Perl interpreter, or by dynaloading (dynamically loading) the module into a running interpreter only when needed. This notion of separable modules is central to the philosophy of both Perl and DBI.
DBI essentially acts as a conduit for the DBD (Database Driver) modules. The DBDs all implement the methods defined in DBI, (e.g. connect()), but in a database-specific way. To clarify this somewhat: Since you, the DBI user, wish to use a completely database-independent programming layer, some part of the system must know how to execute the database-dependent code. That's what the DBD does. The application programmer need never know the DBD is there! All they will be aware of is the database-independent methods defined by DBI. The DBD code is written and maintained by many volunteers and now cover a fairly broad base of database vendors, including Oracle, Informix, mSQL, Ingres, and Sybase. The Web pages listed at the end of this article contain more detailed and up-to-date information about the state of the different DBDs and the DBI as a whole.
Before we even start looking at how you use DBI, you need to download and install the modules. You will always need the DBI module itself, as well as one of the DBD modules for whichever database you have installed. You can download DBI and the DBD modules from the CPAN, details of which can be found on page 20. Please follow the instructions in the files prefixed with README. They are important. They are called README for a good reason. Your ability to get civil answers to your questions depends on familiarity with them!
Next, you need to inform the Perl interpreter that, hey, now would be a good time to load the DBI module in. This always happens before any other DBI work, such as loading one of the database vendor-specific libraries, or attempting to connect to a database should happen. Now, this seems quite obvious, but if I had a dollar for each time....
#!/usr/bin/perl -w use DBI;
And that's it! Honest. If you don't believe me, try this (assuming you're running a Bourne-compatible shell):
$ PERL_DL_DEBUG=2 perl -e 'use DBI;' DynaLoader.pm loaded (/usr/local/lib/perl5 /i486-linux/5.003/usr/local/lib/perl5/usr/ local/lib/perl5/site_perl/i486-linux/usr/ local/lib/perl5/site_perl . /usr/local/lib /usr/local/lib /lib /usr/lib) DynaLoader::bootstrap for DBI (auto/DBI/DBI.so)
See. That simple statement dynamically loads the shared library containing the DBI code into the interpreter, and imports the DBI interface methods, which means we can now start using DBI in anger.
If you refer back to the Architecture diagram on page 15, you can clearly see that all access to the databases are marshalled, or funnelled, through the DBI module. Therefore, we need to make Perl aware of our DBDs. and to do this, we need to use DBI.
To simplify matters, the DBI hides the details of loading the drivers. As you connect to a database with DBI->connect(), the DBI makes sure an appropriate driver is loaded and passes on the request to it. For example:
#!/usr/bin/perl -w
use DBI;
$dbh = DBI->connect( 'connection_string', 'username',
'password', 'mSQL' );
die "Can't connect to database: $DBI::errstr\n" unless $dbh;
loads the DBI driver and then the mSQL driver (since it's not already loaded) and then attempts a connection to the specified database. This call returns a database handle, which we'll see more of later. To use this method for other DBDs, simply change the fourth argument from mSQL to your database engine. If not specified, the value of the DBI_DRIVER environment variable will be used instead.
The connect method will croak() if the driver can't be installed. Otherwise it'll return UNDEF on any other error and $DBI::errstr will contain an error message. The available_drivers() method returns a list of DBI drivers currently installed. Specific drivers can be loaded using the install_driver() method.
Handles are Perl objects returned by various DBI methods which the programmer can use to access data at various abstracted layers. The handles that are used by DBI are as follows and can be seen in the figure below.
)
Driver Handles. A Driver Handle, or drh, encapsulates the database driver itself. The driver handle does not connect you to a database, nor does it let you perform any database operations. It merely acts as a conduit between the DBI and the low-level database API calls. Generally you won't need to deal with driver handles. The DBI does that.
Database Handles. A Database Handle, or dbh, encapsulates a single connection to a given database via a driver handle. There can be any number of database handles per driver handle. For example, if we have a script that copies data from one database to another where both databases are mSQL, then we will have one driver handle but two database handles. In our earlier scenario with a mSQL database and an Oracle database, we would have two driver handles, each with a single database handle.
Statement Handles. A Statement Handle, or sth, encapsulates a command issued to a database via a database handle. As with database handles, there can be any number of statement handles per database handle - or at least as many as the vendor permits. For example, if we have two tables in our database, one containing data and the other containing a stale copy of the data, and we have a program that refreshes the stale copy from the original, we could use two statement handles, one to SELECT the data from the first table, the second to UPDATE the data in the other table. These statement handles would operate asynchronously, if desired, and with the advent of multi-threading, this asynchronous behavior will become extremely powerful. Cursors are simply statement handles for SELECT statements.
Some of the most commonly asked questions on the comp.lang.perl.* newsgroups and DBI mailing lists are "I can't get Oraperl to compile for Perl 5. It only seems to work with Perl 4. What do I do?" and "I've got all this Oraperl/Ingperl/isqlperl stuff and I want to upgrade to DBI, but I don't want to recode it all. What can I do?"
Well, as per usual, we're ahead of you. DBD::Oracle was released originally with an Oraperl emulation layer, a layer of software that translates the original Oraperl API calls into DBI method invocations. The upshot: your existing Oraperl code will now work transparently using DBI and DBD::Oracle, which means you can now start writing new code using the DBI interface, whilst either maintaining the Oraperl code, or migrating it to DBI.
The DBD::mSQL developers are about to release an Msqlperl emulation layer, and there is an isqlperl emulation layer being developed for DBD::Informix.
The volunteer work to formulate a database independent interface for Perl started way back in September 1992, when it was known as DBperl. By the time a Perl 4 version of the specification was just about settled in early 1994, Perl 5 was arriving. Rather than rework the draft specification, an object oriented prototype DBI and DBD::Oracle driver were implemented and released in October 1994 by Tim Bunce. As the modules matured, many volunteers developed drivers for other databases.
The DBI is not without problems. Chief among them is a lack of current documentation. Work is underway to revise the DBperl specification (which, even though rather old, is still a detailed and interesting document). Another issue is the 'narrow' interface currently offered by the DBI. The current minimal functionality is actually intentional, at least in part. It will help to ensure that existing DBI code continues to work correctly when ODBC support is added. ODBC support is the next big item on the DBI agenda. The plan is to add ODBC support into the DBI so that ODBC drivers can be loaded and used in the same way, and at the same time, as the existing DBD drivers. The DBI will also adopt more ODBC/ISO standard conventions, such as the numeric values used to describe data types.
Several resources dedicated to DBI are available on the World Wide Web, via anonymous FTP, and on mailing lists. The mailing lists related to DBI are managed excellently by Ted Mellon. There are three lists to date: dbi-users for general chit-chat and support, dbi-dev for developers to discuss ideas, and dbi-announce for announcements of new driver releases and so on. To join these lists, please see http://www.fugue.com/dbi and use the forms there. Consult the FAQ for how to join the mailing list via e-mail. The DBI WWW pages are located at http://www.hermetica.com/technologia/perl/DBI and should be consulted at all opportunities. The FAQ, DBI Specification and pointers to documentation sources including the mailing list archives are there, among other things. The DBI modules and drivers are available via anonymous FTP from ftp://ftp.demon.co.uk/pub/perl/db. The modules are also available via the WWW pages through the CPAN.
The dbi-users mailing list generally provides good support. The DBI and assorted drivers are in widespread use around the world, often in critical applications. Tim Bunce's company, the Paul Ingram Group, is now offering commercial support for Perl and the Perl 5 version of Oraperl.
We now present some sample code using the DBI interface which should be consulted in conjunction with the documentation available at the resources detailed above. The parameters to the script, which are passed to the connect() method, will vary depending on the database driver being used. All code is available on the TPJ web site.
#!/usr/bin/perl -w # # (c)1996 Alligator Descartes <descarte@hermetica.com> # inout.pl: Connects and disconnects from a database use DBI; die "Usage: inout.pl DbName DbUser DbPassword DbDriver\n" unless @ARGV >= 2; # Create new database handle. $dbh = DBI->connect( @ARGV ); die "Can't connect to $ARGV[1] server: $DBI::errstr\n" unless $dbh; # Disconnect from the database $dbh->disconnect; exit;
#!/usr/bin/perl -w
#
# (c)1996 Alligator Descartes <descarte@hermetica.com>
#
# select.pl: Connects to a database called 'test' on
# a given database, then SELECTs some basic data out
# in array and scalar forms
use DBI;
die "Usage: select.pl DbName DbUser DbPassword DbDriver\n"
unless @ARGV >= 2;
# Create new database handle. If we can't connect, die()
$dbh = DBI->connect( @ARGV );
die "Can't connect to $ARGV[1] server: $DBI::errstr\n"
unless $dbh;
# Prepare the statement for execution
$sth = $dbh->prepare(q{
SELECT id, name
FROM table })
or die "Can't prepare statement: $DBI::errstr\n";
# Execute the statement at the database level
$sth->execute;
# Fetch the rows back from the SELECT statement
while ( @row = $sth->fetchrow ) {
print "Row returned: @row\n";
}
# Re-execute the statement to bring the rows back again
$sth->execute;
# Fetch the data back into separate variables this time
while ( ( $id, $name ) = $sth->fetchrow ) {
print "ID: $id\tName: $name\n";
}
# Release the statement handle resources
$sth->finish;
# Disconnect from the database
$dbh->disconnect;
exit;
#!/usr/bin/perl -w
#
# (c)1996 Alligator Descartes <descarte@hermetica.com>
#
# execute.pl: Connects to a database called 'test' on a
# given database, then EXECUTEs an update # statement.
# This is non-cursorial, so do() is used.
use DBI;
die "Usage: execute.pl DbName DbUser DbPassword DbDriver\n"
unless @ARGV >= 2;
# Create new database handle. Die if we can't connect.
$dbh = DBI->connect( @ARGV );
die "Can't connect to $ARGV[1] server: $DBI::errstr\n"
unless $dbh;
# Execute the statement immediately
$rows = $dbh->do(q{ UPDATE table
SET name = 'Alligator Descartes'
WHERE id = 1 });
die "Statement execution failed: $DBI::errstr\n"
unless defined $rows;
print "Updated $rows rows.\n";
# Disconnect from the database
$dbh->disconnect;
exit;
_ _END_ _