Let's say I'm working with Japanese text and want to search for ![]() (
(![]() means "shoe".) This might be as simple as typing /
means "shoe".) This might be as simple as typing /![]() / when you create your Perl script - as long as your Perl script uses the same encoding as the data being searched. The four popular Japanese encodings (EUC, JIS, SJIS, and Unicode) each use two bytes to encode the single character
/ when you create your Perl script - as long as your Perl script uses the same encoding as the data being searched. The four popular Japanese encodings (EUC, JIS, SJIS, and Unicode) each use two bytes to encode the single character ![]() , but which two bytes depends on the encoding.( 0xB7 0xA4 in EUC, 0x37 0x24 in JIS, 0x8C 0x43 in SJIS, and 0x97 0x74 in Unicode.) Even if we know all about these encodings, Perl does not. As I wrote in my TPJ #2 article:
, but which two bytes depends on the encoding.( 0xB7 0xA4 in EUC, 0x37 0x24 in JIS, 0x8C 0x43 in SJIS, and 0x97 0x74 in Unicode.) Even if we know all about these encodings, Perl does not. As I wrote in my TPJ #2 article:
Text is simply a lump of bytes, and a character encoding tells how to interpret it. Perl regular expressions neither know nor care what encoding the data was intended to be taken as - for the most part, it treats everything in a pseudo-ASCIIish way.
Now, if I'm using EUC, the regex engine considers /![]() / to be exactly the same as a pattern specifying two hexadecimal numbers:/\xb7\xa4/. That's fine, and it means that I can use Japanese (or whatever) any time I want - to Perl, it's all just a bunch of bytes.
/ to be exactly the same as a pattern specifying two hexadecimal numbers:/\xb7\xa4/. That's fine, and it means that I can use Japanese (or whatever) any time I want - to Perl, it's all just a bunch of bytes.
Another assumption we've made, however, is that the match won't start "out of sync" with how characters are encoded. For example, consider the phrase
![]()
encoded in the EUC encoding: The two characters in the middle, ![]() , happen to be encoded via the four bytes 0xA4 0xB7 0xA4 0xA4. This is unfortunate, since the placement of these two characters next to each other creates a two-byte sequence for
, happen to be encoded via the four bytes 0xA4 0xB7 0xA4 0xA4. This is unfortunate, since the placement of these two characters next to each other creates a two-byte sequence for ![]() , 0xB7 0xA4, "by accident." To the regex engine, /
, 0xB7 0xA4, "by accident." To the regex engine, /![]() / is the same as /\xb7\xa4/, and that certainly matches within the effective \xa4\xb7\xa4\xa4 of
/ is the same as /\xb7\xa4/, and that certainly matches within the effective \xa4\xb7\xa4\xa4 of ![]() . It's a case where the shoe fits, but we definitely don't want to buy it.
. It's a case where the shoe fits, but we definitely don't want to buy it.
As I described in my TPJ #2 article, the regex engine attempts to match the regex at each point in the string, bumping along to the next position when no match is found at the current position. The problem in this example is that with a multibyte encoding like EUC, the one-byte bump-along can bump the engine to where it begins a match attempt within a character (at the 2nd byte of a two-byte character, for example). With ASCII or Latin-1 text, a byte is a character, but with many double-byte encodings, a single byte is sometimes a character, and sometimes only half a character.
Specifically, when the attempt of /![]() /starting at "
/starting at "![]() " fails, the bump-along bypasses the first byte of XXX to begin the next attempt at E's second byte. The effective /\xb7\xa4/ can then match that byte and the first byte of
" fails, the bump-along bypasses the first byte of XXX to begin the next attempt at E's second byte. The effective /\xb7\xa4/ can then match that byte and the first byte of ![]() : a "false" match we didn't really want but got because our assumption about bytes and characters was invalid.
: a "false" match we didn't really want but got because our assumption about bytes and characters was invalid.
There exist versions of Perl whose regex engine has been modified to understand the particular mixed-byte conventions of a Japanese encoding (usually SJIS, but that depends on the version). If you use one of these, and if your data and program are in the encoding appropriate to your version, the /![]() / problem goes away.
/ problem goes away.
It's wonderful when it works, but it's a pain for a wide variety of reasons. You're limited to working with only that kind of encoding (and no other kind of text or data), portability is severely limited, these specialized versions tend to lag far behind Perl, and support for the encoding tends to be spotty - consider recognizing multi-byte characters within a character class.
For these and other reasons, I tend to recommend against jperls and the like. Rather, I offer a few techniques that will allow you to work with regular Perl.
Considering our task of finding ![]() , let's think about how to keep the regex engine in sync with what we know to be the start of a character in our EUC encoding. It's rather simple: any byte that matches /[\x00-\x7f]/ represents a single character (the same as ASCII), while any other byte ([\x80-\xff]) is half of a two-byte character. (Actually, three- and four-byte characters are possible, but uncommon, so I'll ignore them in the interest of a simpler example.) To further simplify the discussion, I'll use L as a shorthand for [\x00-\x7f] (low bytes) and H as a shorthand for [\x80-\xff] (high bytes).
, let's think about how to keep the regex engine in sync with what we know to be the start of a character in our EUC encoding. It's rather simple: any byte that matches /[\x00-\x7f]/ represents a single character (the same as ASCII), while any other byte ([\x80-\xff]) is half of a two-byte character. (Actually, three- and four-byte characters are possible, but uncommon, so I'll ignore them in the interest of a simpler example.) To further simplify the discussion, I'll use L as a shorthand for [\x00-\x7f] (low bytes) and H as a shorthand for [\x80-\xff] (high bytes).
The first thing we have to do is take over the job of the bump-along ourselves. We can't really modify Perl's regex engine, but we can write the regex so that:
The first point is easily accomplished by using /^/ at the beginning of the regex. Since /^/ matches only at the beginning of the text, the internal bump-alongs would be useless and Perl eliminates them.
We've seen instances of the second point in earlier issues of TPJ. In TPJ #3, I compared /one/ against /^.*?one/, which uses /.*?/ to apply /one/ at each position in the string until a match is found. But in this case, we can't allow just anything between /^/ and /![]() / - only single-byte characters (that's /L/ in my shorthand) and double-byte characters (that's /HH/). In other words, we ensure that any /H/ is part of a pair. Putting this together yields /^(?:L|HH)*?
/ - only single-byte characters (that's /L/ in my shorthand) and double-byte characters (that's /HH/). In other words, we ensure that any /H/ is part of a pair. Putting this together yields /^(?:L|HH)*?![]() /.
/.
The use of the non-greedy *? instead of * makes what follows, /![]() /, dominant. Each iteration of /L| HH/ will get a chance only when /
/, dominant. Each iteration of /L| HH/ will get a chance only when /![]() / has already failed at the current position, thereby skipping single- and double-byte characters. The key is that we ensure that we stay in sync with the data, never allowing /
/ has already failed at the current position, thereby skipping single- and double-byte characters. The key is that we ensure that we stay in sync with the data, never allowing /![]() / to be applied except where a character starts. Of course, /^/ is instrumental in this: without it, a failure of the first attempt at the start of the string would result in the normal one-byte bump-along. See Quantifier Battles: A Reprise for additional comments about /^(?:L|HH)*?
/ to be applied except where a character starts. Of course, /^/ is instrumental in this: without it, a failure of the first attempt at the start of the string would result in the normal one-byte bump-along. See Quantifier Battles: A Reprise for additional comments about /^(?:L|HH)*?![]() /.
/.
Just for comparison, let's look at a few other approaches to the same problem. Consider the snippet in the next column.
s/L+//g; # remove any L's: they
# can't be part of a
# match of 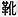 , since
# it's a /HH/.
while (length) {
if (/^/) { # match.
...
last;
}
s/..//; # remove first two
# bytes - actually
# faster than substr!
}
, since
# it's a /HH/.
while (length) {
if (/^/) { # match.
...
last;
}
s/..//; # remove first two
# bytes - actually
# faster than substr!
}
In this example, a raw /^![]() / can be used since ^ anchors the text to the start of the string (and by extension, the start of a character).
/ can be used since ^ anchors the text to the start of the string (and by extension, the start of a character).
Also, consider something like
@chars = m/(L|HH)/g;
foreach $char (@chars) {
next if $char ne '';
# we have a match
...
last
}
For a rather blunt approach, consider
s/HH/HH!/g; if (/
Here, we insert some L characters (the !) to split up H bytes that are adjacent only by coincidence. Since they're now split, we can then use a raw /![]() / without worry.
/ without worry.
Variations on these methods can be used as the needs and conditions arise - these are just a few examples to get the juices flowing!
_ _END_ _
The Japanese fonts in this article were crafted especially for The Perl Journal by Ken Lunde of Adobe Systems, Inc.