In the last issue, Tom Christiansen wrote that regular expressions can still be daunting even to the expert. With much due respect for Tom (from whom I've learned a great deal about both Perl and regular expressions), I don't believe that's really fair to say. Regular expressions need not be difficult, and need not be a mystery. Frankly, if you put aside all the theoretical mumbo-jumbo and look from a practical point of view how the Perl regular-expression engine works, then you too can think along those lines and know how an expression will act in any given situation.
So, I believe that with a bit of explanation and a healthy dose of experience, you'll create an undaunted expert. This story covers the whole range, from the Fred level all the way up to the expert level.
Note that the approach I take for explaining regular expressions is perhaps quite different than you or Fred has ever seen before. The story approaches Perl regular expressions "from the back." The manual page and publications tend to provide a raw "these metacharacters do such-and-such" table along with a few examples. Rather than rehashing this old story, I'll present the view from the regular-expression engine's point of view, showing what it actually does in attempting a match. Eventually, we will work our way "to the front" to see what relation these workings have to the metacharacters you feed it. It's quite a longer path to get there, but the added understanding will usually make the difference between hoping an expression will work, and Knowing.
This is a long story, and because of the "from the back" approach, you might not always see where I'm heading or the relevance of what I discuss. But, as I said, eventually we will indeed work our way to the front, and things should suddenly become much more clear when you start to compare what I've written with the experience and knowledge you already have.
So, if you feel daunted at all - anything less than utmost confidence around even the most hairy regular expression - it is my hope you will get something real, tangible, and useful out of this story. Hey, even Fred did!
Before starting with the story, I'd like to comment on a few of the ways "regular expression" is abbreviated. I use "regex." An alternate spelling, "regexp," also seems somewhat popular although I can't quite comprehend why - it is difficult to pronounce and to pluralize. "Regex" just rolls right off the tongue.
The Story Of Fred
Fred was a happy programmer. Like with so many projects before, Fred needed to verify some data, but this time the data was pretty simple - just numbers and colons. The (small) catch was that the colons must come in pairs, with no singletons allowed.
Mmmm... sounds like a regular-expression match is just the hammer for this nail, and that's exactly what Fred used.
Let's see.... Fred wants to match the line exactly /^ ... $/, allowing a bunch of digits /[0-9]+/ or pairs of colons/::/ as many times as happen to be there /(...)*/. Putting it all together, Fred gets /^([0-9]+|::)*$/.
Well, that was pretty easy, even for Fred. Testing it quickly, he dumps some sample data:
::1234::5678901234567890::::1234567890::888into a file "data" and tests via
% perl -ne 'die "bad data" unless m/^([0-9]+|::)*$/' data %Fred realizes that with this test, no news is good news.
Heck, as an aside, Fred even noticed that this task is so simple that he can use the exact same regex to test it with egrep or awk (two tools, he knows, whose regex flavor is similar to Perl's):
% egrep -v '^([0-9]+|::)*$' data
%
% awk '! /^([0-9]+|::)*$/ { print "bad data" }' data
%
So anyway, Fred's Perl script is happily using this test to verify the data until one day the program just locks up dead. Debugging, Fred tracks it down to the regex match. The match starts, but never returns a result - it seems that there's some infinite loop during the match.
Fred looks at the particular data that was being checked at the time:
::1234::5678901234567890::::1234567890::888:
and notices that it is not valid (this is the valid data from above, but with a singleton ':' tacked onto the end making it invalid).
Dumbfounded, Fred returns to the egrep and awk tests and finds that they still work, even on this data. Fred even tries the same tests on various other machines, all with the same result - the Perl program locks up when it hits this data. So why does the regex match seem to run forever? Fred thinks it's a bug in Perl.
No Fred, it's not a bug in Perl at all - it's simply doing exactly what you asked it to do. "Well," he replies, "I didn't ask it to lock up. And anyway, the egrep and awk tests work fine, so it must be a bug in Perl!" The bug, I'm afraid, is Fred's understanding of Perl and regular expressions (or lack thereof).(Amazingly enough, there is an unrelated bug in versions of Perl 5 before 5.001m which, unfortunately for your author, just happens to result in the test in question appearing to work correctly! From 5.001m that true bug has been fixed, allowing these tests to exhibit the �bug� that this article is about. Fred is cool and up to speed with 5.002.)
The problem is backtracking, something the Perl regex engine has to do, but the egrep and awk engines do not. I'll go into the details a bit later, but the result is that the Perl regex engine needs to perform about 140 billion tests before it can report for sure that the data in question doesn't match m/^([0-9]+|::)*$/. Yes folks, 140 billion. Even on Fred's fastest machine, that's likely to take a few hours, thus exhibiting the "lockup" symptom. [Editor's note: 4 hours on my 175 MHz DEC Alpha.]
The awk, and egrep regex engines, however, are able to find the answer (match, or in this case, no match) immediately. Fred is confused.
The regular expressions that we know and love started out as a formal algebra in the early 1950s, but believe me, I don't want to get into a discussion of math theory (mostly because I don't know it). What is relevant here is that there are two basic methods to implement a regular expression engine: "NFA engines" and "DFA engines."
For those that want to impress their mother, NFA and DFA stand for "Nondeterministic Finite Automata" and "Deterministic Finite Automata," but this is the only time in this article you'll see them spelled out. From a theoretical point of view, there's a lot packed into those terms. But who can figure out all that mumbo-jumbo? For practical purposes, just consider "NFA engine" and "DFA engine" as names, like "Moe" or "Shemp."
Perl has always used an NFA engine, as does vi, sed, GNU emacs, Python, Tcl, expect, and most versions of grep. On the other hand, most versions of egrep, awk, and lex are built with DFA engines. The two types are different in important ways, but practically speaking, you don't need to care about one to study the other. So while this article looks at Perl's NFA engine in depth, a few comments about how NFA and DFA engines differ might be useful to whet the appetite of the curious.
When a DFA engine first encounters the regular expression, it spends some time analyzing it, creating an understanding of every type of string it could possibly match. As a particular string is actually checked, the DFA engine always knows the status (no match, partial match, full match) of the text checked so far. Once the text has been scanned to the end, the engine can simply report the final verdict.
An NFA, on the other hand, goes about things quite differently. It is what I call "regex directed," and approaches a match in a way that humans tend to relate to. For example, if something in the regex is optional, it might try the optional match, and come back ("backtrack") and retry by skipping it if the first try didn't work out.
Each of the two types has its own pluses and minuses, which is why both are still around. A DFA engine tends to need more time and memory for the initial check of any particular regular expression, but because it is determinate and never needs to backtrack, it will tend to do individual matches faster. Sometimes much, much faster. But because of how it works internally, a pure DFA can't provide backreferences or the $1, $2, etc. that Perl's NFA so importantly provides. Chapter 3 of Aho, Sethi, and Ullman's Compilers (a.k.a. The Dragon Book - 1986, 2nd ed., Addison-Wesley) gives an extremely rigorous presentation of the theory behind these engines.
Each program that implements regular expressions has their own special features and special problems. There are "Perl 5.002 regular expressions", "GNU awk 2.15 regular expressions", and so on. While there are obvious similarities among them, there is little meaning to talking "regular expressions" out of context of their intended use. This story is about Perl 5.002 regular expressions.
So, what does all this mean?
Fred has a superficial understanding of regular expressions. He knows more or less what the metacharacters do, but doesn't really understand how a regex match is attempted, and so is never really sure what will happen with anything nontrivial until he actually tries it. He doesn't really understand the differences among regex flavors, so certainly doesn't know about the backtracking that Perl is forced to do. Fred is often confused when regexes that have /.*/ in them don't work as he expects, and he often wonders why he always seems to be getting the wrong results. When it comes down to it, Fred is never really comfortable around regular expressions. Fred is confused all the time.
But you don't have to be like Fred. One nice characteristic of an NFA engine is that it is pretty easy to understand. Understanding how it works will take the magic and the wonder out of Perl regular expressions. You'll be in the know. You'll be confident. You won't be a Fred.
The first thing the regex engine does when it sees a regular expression is to compile it. The regex is analyzed, checked for errors, and reduced to an internal form that can be used later to quickly check a particular string for a match. Since the compilation itself is unrelated to an actual match attempt, it needs to be done just once, usually when the whole Perl script is first loaded. The internal form will then be used repeatedly to do the actual matches during the script's execution.
What this article will focus on is how the engine actually applies a regex to a string to see if there is a match. This is definitely a case where what goes on behind the scenes is not out-of-sight-out-of-mind, for as Fred learned, some matches take much longer than others. As it turns out, we can use our (perhaps newfound) knowledge of what goes on behind the scenes to rewrite the regex that Fred used in such a way that it works quickly in every situation. Fred would be very grateful.
Let's look at the simple regex /".*"/, ostensibly used to match a double-quoted string. From a superficial point of view, this means: "match a double quote, then any amount of anything (except newlines), and finally another double quote."
With the example text
And then "Right," said Fred, "at 12:00" and he was gone.we can easily see that there will certainly be a match, so the question becomes which text will actually be matched. Looking at the English description above, there are a variety of ways it could conceptually apply:
And then "Right," said Fred, "at 12:00" and he was gone.
|<---->|<---------->|<------>|
|<-----|----------->| |
|<-------------------------->|
So which will it be? And more importantly, why?
"The longest match wins" and other myths
If you've been using Perl for more than a day or three, you probably already know that /.*/ is "greedy" and will "match as much as it can," so you probably know which of the above is the result you can expect from Perl. Heck, even Fred knows. Fred knows about "greedy," and has heard various other rules such as "the longest match wins" or maybe "the first match wins" or even "the first longest match wins." Fred can't quite keep them all straight, but feels these rules make him a Power User.
The problem is that none of these rules apply to Perl. As we will see, some are close, but rather than remember a bunch of rules that aren't even correct, I think it is better to Know What Happens. When it comes to complex situations where the "rules" start to fail, your Knowledge will put you light-years ahead of Fred.
Matches that start earlier always take precedence over matches that start later. Why? Because the regex engine first tries to find a match starting at the first position in the text, and only if a match is not found will it then bump along and attempt the match from the next position, and the next, and so on until some individual attempt does yield a match.
Looking at our sample text, we know we can eliminate half of the possibilities because they start later than the three that start at the first quote. We are then left with three possibilities:
And then "Right," said Fred, "at 12:00" and he was gone.
<------>
<------------------>
<-------------------------->
This doesn't explain one way or the other which of the remaining three will be chosen, as they all start at the same equally-leftmost position. But we know that in attempting this match, the engine will make nine failed attempts on matches starting with the 'A', 'n', 'd', and so on.
There's one particularly interesting effect of this "earlier-starting matches take precedence" rule. Let's look at /-?[0-9]*\.?[0-9]*/, which is ostensibly meant to match a floating-point number.(This regex actually appeared in a book written by a friend of mine - but not Fred - for a famous publisher. In the unforgettable words of Dave Barry, "I'm not making this up.") We have an optional minus sign, some digits, perhaps a decimal point, and then perhaps some more digits. Indeed, it will match a wide range of examples such as '1', '3.1415', '-.007', '-1223.3838', '19.', etc. It could even match the '12' from our Fred example.
But will it? Breaking this regex into its component parts, we can view it as
/-?/ and then /[0-9]*/ and then /\.?/ and then /[0-9]*/
The '-' is allowed, but not required. Digits are allowed as well, but also not required. In fact, looking at all the components we realize that nothing is required for a match!
Applying it to our Fred example, the engine will first attempt a match starting from the start of the string. Were it to fail, and fail all the other attempts until the start of the '12',, it would get a chance to match. But since nothing is required to match, we're guaranteed to be successful here with the first try. There is only one plausible match starting at 'And then...', and that's the match of nothingness at the start.
Now, had our text been, say, '4.0, patchlevel 36' there would have been a number of plausible matches right at the start. The nothingness that we know is always allowed with this regex, or perhaps the full '4.0'. Or perhaps just '4.'. All in all, there are five plausible matches. We still don't know anything about which it will be, but whichever it is, we know the match will begin at the start of the text:
Second Cousin of the First Rule: A regex that doesn't require anything for a successful match will always succeed with a match beginning at the start of the target.
So, knowing how the Perl regex engine approaches a string overall, let's look at how any one particular attempt behaves. Knowing this will tell us which of the plausible matches will actually be returned, as well as why. This is where things really get interesting.
A SINGLE MATCH ATTEMPT
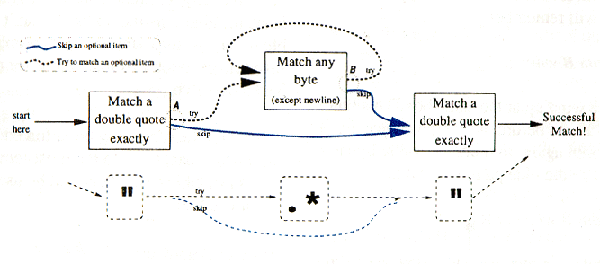
The top half of the above figure shows, from a practical point of view, how the regular expression engine views /".*"/. The bottom half shows the metacharacters relating to the top half.
It helps to consider the regex engine as an entity moving from square to square along the black and blue connecting lines. If it moves into a square and can make the match noted there, it is then free to move along. If not, it must do something else (that "something else" being backtracking, but I'm getting a bit ahead of myself).
Sometimes there is more than one path the engine can take at any one point. In the figure, these are marked A and B. It is useful to note that the blue paths represent the skipping of something that is allowed but not required (i.e. optional). The dashed black path from A represents an attempt at /.*/, while the blue path represents its omission. The omission reflects that /.*/, can match nothing yet still be successful.
The black path from B represents the attempt at another /./ by the /.*/ construct, while the blue path represents breaking out of the /.*/, to continue on. This reflects that no matter how much has already been matched by /.*/, further matches are still optional.
Perl's NFA regex engine can take only one path at a time, so at these places where there are more than one option, what should it do? This is an extremely important point. It may well be that one path will lead to a match, while others will not. The point is, the NFA regex engine doesn't know which will and will not lead to a match until it actually tries.
Looking at the figure and starting at the marked position in
And then "Right," said Fred, "at 12:00" and he was gone.
Indeed the first "match a double quote" box is successful. This moves us to Right, in the text, but the engine still has to move to another box. At A it has the choice between the blue and black arrows. If it happens to choose the black path over to the second "match a double quote" box, we can see it will fail, since a double quote won't match the 'R' we're currently at. We can see it will fail, but the regex engine can't. Remember, it doesn't know until it actually tries.
Which will it choose? What will it do if it chooses wrong? These are the key, fundamental issues of an NFA regex engine. If you understand them, you are 90% of the way to becoming an undaunted expert.
Fortunately, as you'll see, these issues are quite easy to understand.
When the regex engine is faced with multiple paths, it chooses one (exactly which it chooses and why is quite important, but discussed a bit later), and marks the others paths as untried. Later during the match, if the regex engine finds it has taken a path that has lead to failure, it can return to the situation where it had been and retry with one of the marked paths. This is known as backtracking.
Returning to our example, we found ourselves in the text at Right, and in the regex at A. For the purposes of discussion, let's say that the regex chooses the blue path first. In doing so, it will remember that, should the need ever arise, it can retry from that position via the black path.
Indeed, the need arises quickly. As mentioned above, the second "match quote" box certainly fails to match the 'R'. Normally, this local failure would mean overall match failure, but because we have a remembered state, we know that there are options that were allowed but have not yet been tried. Backtracking is nothing more than returning to yet-to-be-tried options when the current path fails.
So, we return to A and take the black path. This time, the "match any byte" successfully matches the 'R'. Now what to do? At B now, we again have a choice. For the purposes of the current discussion, let's say that the black path is chosen. In doing so, the engine will remember
can take the blue path from B while at R
So, taking that black path we wind up at the same box. This time, the any-byte matched is the 'i'. As before, we have a choice. Let's say that the black path is chosen again. In doing so, we're bypassing another opportunity to take the blue path, so we add
can take the blue path from B while at Ri
to our list of remembered states. In fact, we add a state each time we go through this loop. Assuming we take the black path the next time as well, we also add
can take the blue path from B while at Rig
during the next loop, leaving us at Righ in the text.
Let's say, for the purposes of the discussion, that at this point the regex engine decides to take the blue path. Now we're bypassing a chance to take the black path at this juncture, so we add
can take the black path from B while at Righ
Unfortunately, the blue path from B at this point immediately leads to failure, as the text's 't' can't match the required double-quote. A local failure? No problem! We have plenty of saved states to retry from, and one (or more?!) might eventually lead to a match.
When the regex engine is forced to backtrack, it will always backtrack to the most-recently saved state that is available (the others will be used, in turn, when and if needed).
So we backtrack to
can take the black path from B while at Righ
and take the black path. We match the 't' and find ourself at B for about the half-dozenth time, and as with each time before, we have two fresh choices.
Okay, so this description is getting a bit long-winded, and I think by now even Fred is getting the picture. And we still haven't gotten to the whole issue of how the engine decides which from among its possible paths to choose at any particular point (remember, all the decisions reported above are for the purposes of discussion and don't necessarily reflect what any known regex engine will actually do in the exact same situation).
So, to make this go a bit quicker, let's assume that from now on the regex engine will always chose the black path whenever it reaches B. This would result in a lot of looping, with the "any byte" matching each byte of the target text in succession. And, of course, each time we choose the black path, the blue is remembered in yet another saved state.
By the time the engine has neared the end of the string, as far as 'was gone' we have accumulated quite a few saved states. Listing them in reverse order, we have
can take the blue path from B while at was gon
can take the blue path from B while at was go
can take the blue path from B while at was g
...
can take the blue path from B while at Rig
can take the blue path from B while at Ri
can take the blue path from B while at R
Anyway, that's the current status, but we still haven't reached an overall match yet. As we've been doing, we take the black path, this time adding
can take the blue path from B while at was gone
We can match the '.', and so follow with another black path, adding
can take the blue path from B while at was gone.
But this time, the "any byte" box can't match because we're at the end of the string. Had it been a "match the end of the text" box, we'd be fine, but it's not, so we have a local failure and need to backtrack. So we go back to this most-recently saved state, but fail there as well (this time because "double quote" can't match the nothingness at the end of the string). Still no worries - we have plenty of saved states. The most recent is now
can take the blue path from B while at was gone
but this also fails: a double quote and a period don't mesh. In fact, the next dozen or so backtracks fail in the same way. It's only when we finally backtrack to
can take the blue path from B while at 12:00
that the double quote can match. Once done, there is only one path from that box, so no decision needs to be made nor any new state saved. And as it turns out, we have an overall match!
And then "Right," said Fred, "at 12:00" and he was gone.
<---------------------------->
Now that we've reached an overall match, we can consider ourselves done. Sure, there are some other saved states that may well also lead to overall matches (actually, there are two others still in there), but since we have a match already, who cares? (Answer: a POSIX engine might, but not Perl).
Thus, we come to the rule
Note that this is not "the shortest match" or "the first match I see" or "the match I, as a programmer, am hoping for," but the first match that the regex engine actually reaches.
The decisions about which path to take at any particular point has a direct influence as to which match the regex engine will find first.
Now remember - and I can't stress this enough - that the decisions about which path to take have thus far in this article been randomly chosen off the top of my head and have no necessary relation to any reality. I wanted to explain the mechanics of how backtracking works, and do so without muddying the waters with the (equally important) issue of path selection. Had I happen to write the story such that the regex engine made different decisions, the results could have been different.
For example, had I decided that during the "any byte" loop, as the regex matched up to 'Fred, at' the engine suddenly decided to take the blue path, we would have immediately matched the double quote and then reached the overall match
And then "Right," said Fred, "at 12:00" and he was gone. <-------------------->
Or, as another example, had I written that the blue path was suddenly chosen as the engine came up to 12:00 and, we would have reached the same match as in the story, but in quite a more efficient way. In the original story, we'd matched all the characters of ' and he was gone.' only to have to effectively undo that by backtracking to the final double quote. So this illustrates two different avenues to the same match, one with a lot of what turns out to be extra work and one without.
Before getting into the details about which path is chosen, let's look at the various regex constructs that yield multiple choices in the first place. The quick summary is that when something is optional, the regex engine needs to decide if it should first attempt to match the optional part, or if it should first try the overall match skipping this optional part. Each choice represents a path, and in either case the choice not taken is remembered for later use if backtracking so dictates. So remember, something optional means multiple paths.
The most basic "optional" item is anything governed by ?, such as the /(blah)/ in /(blah)?/M. We know that Perl's new ?? means optional as well, and that it is "non-greedy," but what does that really mean? It is directly related to path selection (you'll be able to cast aside any shroud of mystery you might have about this in just a moment), but first I'd like to continue summarizing items that are considered optional.
Items governed by * (and *?) are optional not only once, but repeatedly forever (well, to be pedantic, Perl currently has an internal limit of 32K repeats for parenthetical items). Almost the same, items governed by + and +? are optional only after their first match (the first match being required). Items governed by {min,max} and {min,max}? are optional once their required min matches have been made, and are only optional until the max has been reached. With {num}, nothing is optional (which, as you might realize, is why {num}? is always exactly the same as {num} - there is no difference whatsoever).
Let's not forget about alternation. With something like /moe|fred|shemp/, if /moe/ is attempted first, it is optional because its failure does not mean the entire regex necessarily fails, since /fred/ and /shemp/ are still available. If indeed /moe/ fails and, say, /shemp/ is tried next, it too can be considered optional because there is still the /fred/ left to try. But if /shemp/ also fails, then /fred/ suddenly becomes required, since its failure results in no more alternates. Thus, alternates are optional as long as there are other alternates left to try.
When alternation is surrounded by parentheses, this "failure" becomes failure of the component, not of the entire regex. For example, failure to match any of the alternates in /(moe|fred|shemp)?/ doesn't mean overall failure since matching any of the alternates was optional via the ? in the first place.
Character classes
One quick note about character classes. A character class alone does not represent anything optional. /[xyz]/, for example, does not mean "try to match x, or match y, or match z" (that would be /x|y|z/). Rather, /[xyz]/ means "let's check out one byte, and if it is an x, y, or z, we match" It is a subtle distinction in English, but a huge distinction to the regex engine. It should be apparent that the character class is much more efficient than the /x|y|z/, which might perform up to three separate matches rather than the one check required by /[xyz]/.
A negated character class (such as /[^xyz]/) is no more or no less efficient than a normal one. The meaning of the list of characters is simply toggled from "these allowed" to "something except these allowed."
All the other regex constructs, from ./^/ to /\b/, to /(?!...)/, to /\3/,, do not represent anything optional. They may well become optional when governed by something mentioned above, but there is nothing intrinsically optional about them.
Finally, the last piece of the puzzle! We know about saving states for untried paths, and we know about using those states to backtrack if needed. Only one question remains: when faced with multiple paths, which one will the Perl regular expression engine actually attempt first?
Rephrasing the above in a more human point-of-view, when faced with an optional item (or with alternation items), will the Perl regular expression engine first attempt to match the optional item, or will it first attempt to skip the optional item? (Or in the case of alternation, in which order will the items be tried?)
?, *, +, and {min,max}, the so-called "greedy" or "maximal matching" metacharacters, will always attempt an optional item first. They will skip an optional item only if forced via backtracking.
??, *?, +?, and {min,max}?, the so-called "ungreedy" or "minimal matching" metacharacters, will always skip an optional item first. They will return to try matching the item only if forced via backtracking.
With alternation, Perl always attempts the alternates in order (counting from left to right). The first alternate will always be attempted first. The second and subsequent alternates will be attempted (in turn) only if so forced via backtracking.
If I were telling about Japanese instead of regular expressions, the point we've reached would be comparable to my having told you 90% of the grammar rules and vocabulary of the Japanese language. Were that the case, I certainly wouldn't expect you to start jabbering away in Japanese - it takes time and experience to internalize the information and to draw out the relevancy to what you already know about human communications or, as the case may be, Perl regular expressions.
So far I've given you motions, but no directions. Words, but no acting. Fred has this funny look on his face, not really sure if he understands why he's been listening for the last hour. Depending on your previous exposure to Perl regular expressions, you might well be thinking "wow, so that's why such-and-such turns out that way!" But for most, I think the lessons of this story require a fair amount of real-world context before they sink in completely.
As I noted early on, even Fred knew that /".*"/ would match
And then "Right," said Fred, "at 12:00" and he was gone. <---------------------------->
But rather than "because /.*/ is greedy", I think it would be instructive to carefully run through the match sequence yourself, counting tests, saved states, and backtracks. This will explain in a very tangible way why /".*"/ does not match
And then "Right," said Fred, "at 12:00" and he was gone. <----->
as many new Perl hackers expect. Furthermore, applying the same rigorous step-through to /".*?"/ will clearly show why it does match 'Right,'.
Really, please try working through these examples on your own. In the next issue of TPJ, I'll focus much more on how to put these mechanics to practical use, but to use them effectively you must understand them completely. Working through these two simple examples is a good start.
As you work through them, keep a tally of how many individual tests are performed (such as "does 'match a double quote' succeed?"), noting how many are successful and how many fail. Keep a count of how many times you have to backtrack, and also note exactly how many states are discarded as no longer needed once the overall match is found. For the purposes of all these counts, start counting with the first successful match of the leading /"/ as test (and match) number 1. Once you feel comfortable that you understand how the matching proceeds, you can check your answers with the chart in the Match Statistics .
Oh, and as a bonus, it should be quite instructive to do the same work-through with /"[^"]*"/. The associated statistics are also included in the sidebar.
And in the next issue, I'll start to develop some working rules and conclusions from all this (but hopefully you'll be able to make some of your own as you start to re-examine what you already know in this new light).
By the way, I guess I should make one mention about how Perl sometimes optimizes how it deals with regular expressions. Sometimes it might actually perform fewer tests than what I've described. Or it perhaps does some tests more efficiently than others (for example, /x*/ is internally optimized such that it is more efficient than /(x)*/ or /(?:x)*/). Sometimes Perl can even decide that a regex can never match the particular string in question, so will bypass the test altogether.
These optimizations are interesting, but the base workings are much more important. Once you've got that down pat, you might start to delve into the nitty-gritty details enough such that you can attempt to incorporate an understanding of them into your regular expressions.
Oh, and one final item before I close the article. Fred is still asking why on earth his /^([0-9]+|::)*$/ was taking so long. In a future column, I'll talk much more about this issue, which can rear its ugly head in more than just Fred code - it can be rather common. But until then, I'll let you help Fred. Do the work-through of applying this regex to the text '12:'. We know it will fail, but the regex engine doesn't until it tries all the matching and backtracking that this whole article has been about. Then try the text '123:', and if you still don't get the picture, try '1234:'. I hope the reason becomes clear and you can explain it to Fred instead of being a Fred.
__END__
Jeffrey Friedl works at Omron Corp (Kyoto, Japan), and spends his copious free time on a regex book for O'Reilly. He can be reached at jfriedl@omron.co.jp.