2008-12-13 Creativity In Free Software
Reading the blog of Frédéric Péters, I stumbled upon his post called "Vers l'infini et au-delà !". I quickly commented as I share a similar feeling about the recent development of the relationship between software "industries" and free software. Frédéric pointed out the recent "2020 FLOSS Roadmap" report where the roadmap is more a tentative to be close to the fuzzy and vague Magic Quadrant than something really coming from the free software community (yep, the community is not only composed of "industrial consortium" even if this report is trying to give this idea).
My feeling is the following : there are no way to predict the future especially while we are talking about (free) software evolution. Roadmaps are more close to science-fiction books (I prefer to read science-fiction books that's more fun) than something else. Why it's like that? Just because software development is a trial-and-error process and especially in the free software community. Free software users also choose their free software by trial-and-error… how can you easily predict the state of free software in 2020 when a trial-and-error process is in use? This reminded me again of the post from Linus Torvalds about "sheer luck" design of the Linux kernel. To quote him :
And don't EVER make the mistake that you can design something better than what you get from ruthless massively parallel trial-and-error with a feedback cycle. That's giving your intelligence _much_ too much credit.
Projecting in 2020 what will be the Free Software is just a joke. What we really need to do to ensure a future to free software is to ensure the diversity and the creativity dynamic in the community. Creation and development of free software without boundaries or limitation is critical to ensure a free future. New free software development often comes from individuals and not often from large industrial consortium… So the roadmap is easy : "Resist and create free software".

Tags: freesoftware diversity biology freedom
2008-12-21 Scientific Publications and Proving Empirical Results
Reading scientific/academic publications in computer science can be frustrating due to various reasons. But the most frequent reason is the inability to reproduce the results described in a paper due to the lack of the software and tools to reproduce the empirical analysis described. You can regularly read reference in papers to internal software used for the analysis or survey but the paper lacks a link to download the software. Very often, I shared this frustration with my (work and academic) colleague but I was always expecting a more formal paper describing this major issue in scientific publication especially in computer science.
By sheer luck, I hit a paper called "Empiricism is Not a Matter of Faith" written by Ted Pedersen published in Computational Linguistics Volume 34, Issue 3 of September 2008. I want to share with you the conclusion of the article :
However, the other path is to accept (and in fact insist) that highly detailed empirical studies must be reproducible to be credible, and that it is unreasonable to expect that reproducibility to be possible based on the description provided in a publication. Thus, releasing software that makes it easy to reproduce and modify experiments should be an essential part of the publication process, to the point where we might one day only accept for publication articles that are accompanied by working software that allows for immediate and reliable reproduction of results.
The paper from Ted Pedersen is clear and concise, I couldn't explain better that. I hope it will become a requirement in any open access publication to add the free software (along with the process) used to make the experiments. Science at large could only gain from such disclosure. Open access should better integrate such requirements (e.g. reproducibility of the experiments) to attract more academic people from computer science. Just Imagine the excellent arxiv.org also including a requirements in paper submission to include a link to the free software and process used to make the experiments, that would be great.
Tags: openaccess research education freesoftware
2008-12-24 Oddmuse Wiki Using Git
If you are a frequent reader of my delicious feeds, you can see my addiction regarding wiki and git. But I never found a wiki similar to Oddmuse in terms of functionalities and dynamism relying on git. Before Christmas, I wanted to have something working… to post this blog entry in git. The process is very simple : oddmuse2git import the raw pages from Oddmuse into a the master branch of a local git repository. I'm using another branch local (that I merge/rebase regularly with master (while I'm doing edit via the HTTP)) to make local edit and pushing the update (a simple git-rev-list --reverse against the master) to the Oddmuse wiki. The two scripts (oddmuse2git git2oddmuse) are available. Ok it's quick-and-dirty(tm) but it works. There is space for improvements especially while getting the Oddmuse update using RSS to avoid fetching all the pages.
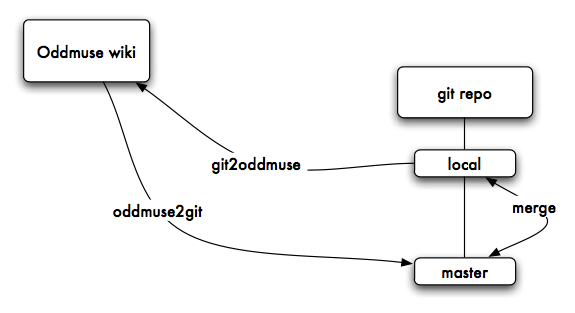
Update - 20th December 2008 : I imported communitywiki.org using my oddmuse2git and update seems to work as expected. If you want clone it :
git clone git://git.quuxlabs.com/communitywiki/
I also updated the script to handle update (using the rc action from Oddmuse) to only fetch the latest updates. For more information about Oddmuse and Git.

