)
| Requirements |
|
Apache http://apache.org
Embperl CPAN/modules/by-module/Apache |
"Because mod_perl is, frankly, scarier than a typical Apache
module."
-Jon Udell, Byte March 1998
While it may be scarier than most Apache modules, mod_perl is also one of the more powerful additions available. In TPJ #9, Doug MacEachern (author of mod_perl) and Lincoln Stein (of CGI.pm fame) presented an introduction to mod_perl. This article builds on their foundation and demonstrates a full-fledged mod_perl application that lets users provide feedback on web documentation. I'll also describe some of the performance concerns and how your Apache configuration should be modified to make the most of mod_perl.
Most people are familiar with CGI (Common Gateway Interface) scripts written in Perl that add dynamic content generation to a web server. In addition to CGI, most web servers provide some sort of interface that allows code to be run inside the server, such as NSAPI for Netscape and ISAPI for Microsoft.
Apache lets you create a chunk of code, called a handler, that is invoked when the server fulfills a browser's request. That might happen when a URL is translated into a local pathname, or when a child process terminates.( Not all handler hooks are available in all versions of Apache. For example, the child exit hook mentioned above is only available in Apache 1.3 and higher.) mod_perl embeds a Perl interpreter within each Apache httpd process, giving you the ability to write handlers in Perl instead of C.
Aside from exposing the Apache module API, mod_perl also provides other benefits, such as running existing CGI scripts inside the persistent interpreter, and letting you configure Apache with Perl code enclosed in <Perl></Perl> and placed in your server configuration files. You can do anything from setting the port Apache listens for requests on, to configuring virtual hosts based on the contents of a database. For more information on <Perl> configuration, see the online mod_perl.pod document bundled with the mod_perl distribution.
There are several possible ways you can use mod_perl to speed up your web applications, including:
Each has its own particular strengths and weaknesses.
If you already have existing CGI scripts written in Perl, the Apache::Registry module lets you run them with little (if any) changes--but much more quickly because the Perl interpreter is already resident in memory. The first time a URI is requested, Apache::Registry compiles the CGI script and stores a reference to the compiled code. Forever after, the program is run within the child httpd process, rather than launching a new Perl process each time.
In essence, Apache::Registry wraps up your entire existing script as a subroutine named handler() inside a package named after the script's name. It then calls this precompiled handler whenever the corresponding URL is accessed. If the file containing the script changes on disk, Apache::Registry notices and recompiles the code.
This example, modeled after a slide from Doug's Perl Conference presentation, shows the code that Apache::Registry wraps around a CGI script. The contents of the script are read into a string. Everything up until the local $^W = 1; is prepended by Apache::Registry, and it appends the last }. The entire string is then passed to Perl's eval function and compiled.
package Apache::Root::mp::example_2epl;
use Apache qw(exit);
sub handler {
#line 1 /usr/local/apache/mp/example.pl
local $^W = 1; #!/usr/bin/perl
use CGI;
my $q = CGI->new;
my $them = $q->remote_host;
print $q->header( 'text/html' ),
$q->start_html(-title => 'My Apache::Registry Example');
print <<EOT;
<h1>My Apache::Registry Example</h1>
<p>Hello browser at $them.</p>
EOT
print $q->end_html;
}
One caveat: Not all CGI scripts run without modifications (for example, those with __DATA__ or __END__ tokens won't run at all). Also, by the time Apache::Registry kicks in, several stages of the request (such as user authentication and authorization) have already finished. So just as with regular CGI scripts, you don't have any way to authenticate or authorize users.
On the positive side, most any web server will have some sort of capability to run CGI scripts, making it easy to port to and from non-Apache web servers. And since CGI is so widespread, programmers can easily leverage their existing web scripting knowledge while enjoying the reduced overhead. For more information on Apache::Registry, see the file cgi_to_mod_perl.pod which comes with mod_perl, or read it on the web at: http://perl.apache.org/dist/cgi_to_mod_perl.html.
Also see Lincoln's article on Stately Scripting with mod_perl in TPJ #9.
In addition to faster CGI service, another popular reason to use mod_perl is for fast Embperl processing. This module allows Perl code to be embedded within HTML documents, just like the standard Apache SSI (Server Side Include) module mod_include. The Perl code should appear between one of four delimiters; which delimiter you use determines what Embperl does with your code.
[+ Perl code +]
Replaces the code with what it evaluates to.
[- Perl code -]
Executes the Perl code invisibly.
[! Perl Code !]
Same as [- Perl Code -], but the code is only executed the first
time it's encountered. This is used to define subroutines and perform one-time initialization.
[$ Command Arg $]
Executes an Embperl metacommand. The commands (e.g. if
and while) are listed in the Embperl documentation.
Embperl also understands HTML and is capable of dynamically generating tables, lists, and form selection buttons. Here's an example taken from the Embperl manual page that prints the contents of the environment:
[- @k = keys %ENV -]
<TABLE>
<TR>
<TD>[+ $i=$row +]</TD>
<TD>[+ $k[$row] +]</TD>
<TD>[+ $ENV{$k[$i]} +]</TD>
</TR>
</TABLE>
The first line sets @k to the names of the environment variables and produces no output; that's why the minus signs are used as delimiters. Embperl then parses the table and looks for use of any of three special variables: $row, $col, or $cnt. If none are found in the table it is passed through with no modification. If they are used, Embperl repeats the text between <tr></tr> as many times as there are elements in @k.
As with Apache::Registry, Embperl processes pages only after many other stages of the request have finished. Code is compiled once and cached, giving much better performance over other similar embedded constructs such as mod_include.
The last alternative is writing your own request handler directly, using Apache.pm to access the Apache API. Under the hood, this is exactly what Apache::Registry and Embperl do. You can create handlers for each step that Apache takes to respond to a request. Handlers can be used to provide access control, to rewrite incoming URLs, or to implement custom logging, such as logging to a database system instead of a log file. Apache.pm lets you do everything in Perl that you can do in C.
package MyHandler;
use Apache::Constants qw(:common);
sub handler {
# $r contains Apache request object
my $r = shift;
# $them is the client's hostname or IP
my $them = $r->get_remote_host;
$r->content_type( "text/html" );
$r->send_http_header;
print qq{
<html>
<head>
<title>My First Handler</title>
</head>
<body bgcolor="#ffffff">
<h1>My First Apache Handler</h1>
<p>Hello to the browser at $them.</p>
<p>Here are the headers your browser sent me:</p>
<pre>
};
my %headers = $r->headers_in;
foreach ( sort keys %headers ) {
$r->print( "$_: $headers{$_}\n" );
}
print qq{
</pre>
</body>
</html>
};
return OK;
}
1;
Now you have direct access to the entire Apache API. In contrast, CGI and HTML::Embperl pages are limited to executing during the content generation phase, while handler routines can run at any of the fourteen different stages. However, if you aren't familiar with the Apache API, you might find writing your own handlers a bit daunting since it requires detailed knowledge of how Apache handles requests. For generating simple dynamic pages, Apache::Registry/CGI and Embperl perform admirably.
While mod_perl is a great improvement over vanilla CGI, you should be aware of some of the issues involved in squeezing the most efficiency from it. If you're just running a small web application on its own dedicated machine used inside your company by twenty people, you might not be that concerned. But if your site is intended for a large audience you need to be aware of these issues.
Preload your modules. One of the biggest items to be aware of is the fact that each Apache process with mod_perl requires more memory than one without mod_perl. This can cause performance to suffer if your system runs out of physical memory and needs to swap out to disk. This PerlModule configuration directive can help; it causes mod_perl to load the named module (or modules) at server startup:
PerlModule CGI Apache::Registry MyFavoriteModule
Preloading modules that will be used by your scripts improves the performance of requests and reduces the amount of memory needed, since the memory can be shared between all the processes. (Whether this actually buys you anything depends on how your operating system handles shared memory between spawned processes.) While modifying Perl modules used by your application, you might want to set PerlFreshRestart On in one of your server configuration files (e.g. httpd.conf). Otherwise, Apache won't know to reload your Perl modules when it next restarts, and you won't see any changes you have made.
Use multiple servers. Another performance enhancement is to run multiple servers. You can run servers on different ports on the same machine, or on different machines entirely. One server can have mod_perl installed for all content requiring it, and another without mod_perl for static content such as images. With the Apache mod_proxy module or Squid (an HTTP cache/ proxy program) you can make the multiple servers appear as one.
For a more thorough discussion of tweaking mod_perl to get the most performance from it, see the mod_perl_tuning.pod document bundled with the mod_perl distribution. Information on configuration directives such as PerlModule can be found in the mod_perl.pod online documentation.
To demonstrate how to use mod_perl to create applications, we'll develop a site which provides documentation (such as FAQs, tech notes, and white papers) to customers, and accept feedback on which documents are the most helpful and most used. The idea comes from a paper presented at last year's Perl Conference by Dav Amann of Netscape on the customer support site they developed using Perl. The site (http://help.netscape.com/) allows customers quick access to the most frequently requested tech notes, and allows customers to give feedback on the documents to Netscape (both a simple yes-or-no "This document answered my question" as well as a more detailed questionnaire). A sample is shown in Figure 1.
Figure 1: A footer added to every document by Apache::Sandwich.
Our sample application will manage a document tree, provide a count of the number of hits for each document within the tree, and allow readers to rate each document from 1 to 5. Our application will use a little bit of all three approaches: CGI scripts, Embperl pages, and Apache handlers.
A handler routine will be used during the PerlTransHandler stage so that we can map URIs to filenames based on a database. This translation handler will also arrange for another handler to be called during the log phase to update the hit counts in the database for each file. An Embperl document will be used to dynamically generate an index of the most frequently accessed documents based on the contents of the database. Finally, two CGI scripts will be used to record user feedback and manage adding and removing files. In addition to the modules we develop, we'll be using several existing Perl modules to handle access control and adding footers to pages.
There are many Perl modules available for use with mod_perl and Apache; a complete list of Apache specific modules is available at: http://perl.apache.org/src/apache-modlist.html. All modules should also be available from your favorite CPAN mirror. A quick introduction to the modules used in the sample application follows. Here, we use five modules: DBI, Apache::DBI, Apache::AuthenDBI, Apache::AuthzDBI, and Apache::Sandwich.
DBI is a Perl module that provides a consistent method of accessing most any relational database system from Perl. You use the same Perl methods regardless of which database you're using. Different database driver modules (DBDs) handle the database-specific API so you don't have to.
Apache::DBI improves the performance of DBI by caching database connections. Opening a connection to a database often takes a lot of time, so Apache::DBI maintains a cache of open database handles. As long as Apache::DBI is loaded before the DBI module, all connect requests will be handled by Apache::DBI. One limitation of the cache: You cannot create database connections in the parent Apache process and have them shared by child processes.
For developing the sample application I used the freely available Postgresql: (http://www.postgresql.org/) and its driver, DBD::Pg.However, any database for which you have the proper DBD::module installed should work. Postgresql is an SQL database; if you aren't familiar with SQL, an excellent tutorial is available at: http://w3.one.net/~jhoffman/sqltut.htm.
These two modules allow you to store authentication (i.e. usernames and passwords) and authorization (e.g. group membership) information in a database accessed via DBI. To use these modules, you must have enabled the appropriate Perl handlers when you built mod_perl. See the Apache::AuthenDBI documentation for the required handlers, and the INSTALL file in the mod_perl distribution to learn how to enable handlers at build time.
This module allows you to "sandwich" a page's contents between a header and footer without modifying the page's source. Apache sends the headers, then the contents of the requested URI, and finally the footers. We'll use this module to append an HTML form that lets users provide feedback on the usefulness of the documents. Thanks to Apache::Sandwich, we won't have to modify any of our documents to add these footers.
Database Setup. The first task is to create the tables in our database. The documents table keeps track of the title and number of hits for each file being tracked. The rating and raters fields are used to calculate the average rating given to the document by readers. Several indices are created to maintain unique entries and to speed up queries. The other table, users, maintains username and password information for Apache::AuthenDBI. In this case, Apache::AuthenDBI is probably overkill for the minuscule number of users we'll be concerned with, but we'll stick with it for instructional purposes.
In addition to creating the tables, you'll probably want to create a user account for use by Apache; we'll use ap_auth in the examples that follow. The SQL code to create the tables can be found at: http://www.tpj.com/programs/Issue_11_mod_perl/tables.sql.
TopTenTrans.pm. Our application uses a PerlTransHandler to customize the mapping of URIs to filenames. A translation handler can change the default mapping of URIs to filenames. Similar to Apache's <Alias> configuration directive, the TopTenTrans::handler subroutine modifies the filename to which URIs with a specified prefix resolve.
)
Figure 2: An Embperl-generated table.
The translation handler also allows us to map URIs based on the database contents. For example, the fifth most useful document will be accessible as http://server/topten/5. The handler connects to the database and retrieves the corresponding record, and then sets the filename accordingly. Later stages will use this information to return the contents of the request.
The translation handler requests that Apache let mod_perl handle the content generation phase of the request, and that mod_perl should use Apache::Sandwich as the PerlHandler to generate the content. This is the runtime equivalent of placing these lines in the access.conf:
SetHandler perl-script PerlHandler Apache::Sandwich
Lastly, the handler arranges for a subroutine to be called during the logging phase of the request (after the page has been sent) using Apache::push_handlers(), which allows a Perl handler to specify which handlers should be called during later phases. The TopTenTrans::log_hit() subroutine increments the hits field in the database record for the corresponding file.
This facility is often useful if you have a long-running task but
don't want to delay sending a response back to the client until it
is complete. On an extremely busy site, the overhead of updating
the hit count for each file immediately might be too much of a
load; one possible solution is to keep the statistics in memory
using the IPC::Shareable module and then periodically send the
statistics to the database using a log handler subroutine. The
TopTenTrans.pm module can be found at: http://www.tpj.com/programs/Issue_11_mod_perl/TopTenTrans.pm.
index.epl. The next component is the document index, which can list all tracked documents or just the top ten. This is implemented using Embperl to generate the listing on the fly. Why use Embperl? Because the index page is just a table, which is a snap to create with Embperl's dynamic table generation facilities.
Depending on whether it is called with a query string of
all (that is, http://server/topten?all versus http://server/
topten), the embedded code pulls the appropriate information
from the database and stores it in an array reference. Embperl's dynamic table generation creates an HTML table listing the rank, title, hits, and rating for each document.
rateit. The Apache::Sandwich routine appends a file, rate.html, to each document which contains a form the user can use to rate how useful they found the document. The results will be processed by a CGI script called rateit that computes the new rating.
There isn't anything mod_perl specific about rateit, so we won't go into much detail about it. If the user didn't select a rating, the script asks them to use the back button and select one. If they did check one of the boxes, the script retrieves the current rating and the number of people who have submitted ratings from the database, uses these values to calculate the new rating, and updates the database with the new information. The script then prints a message with the user's choice, the new rating, and links back to the document and Top Ten index.
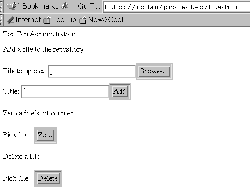
Figure 3: The ttadmin CGI script uses DBI to modify the document repository.
ttadmin. The last component we need is some method of administering documents. The ttadmin script provides a means of adding new files to the repository, zeroing the hit count for a file, and deleting a file from the repository. When called with no parameters, it returns a page with three forms on it: one to let the user specify a file to upload; another form get a page from which to choose a file to zero the hit counter for; and one to retrieve a listing so that the files can be deleted from the repository. Like rateit, ttadmin is pretty much a vanilla CGI script. The section that adds a file simply copies the uploaded file into the Top Ten root directory and adds the appropriate information to the database. The counter zeroing and deletion routines use the list_all_files() subroutine to generate a table listing all of the entries from the database if called with out the victimfile query parameter being set. If the parameter is set, the appropriate changes are made to
the database.
index.epl, rate.html, rateit, and ttadmin can all be found at: http://www.tpj.com/programs/Issue_11_mod_perl/.
Now that the code has been written, you'll need to place all of the components in the correct locations and let Apache and mod_perl know where to find them. In the configurations below, I have Apache installed in /usr/local/apache and the Top Ten root directory is located in /home/fletch/topten. The Top Ten repository appears
under the URI http://servername/topten/. Your copy of
mod_perl should have been compiled with at least PERL_TRANS,
PERL_AUTHEN, PERL_CLEANUP, PERL_STACKED_HANDLERS,
PERL_SECTIONS, and PERL_SSI enabled. See the INSTALL file that comes with mod_perl for more information.
httpd.conf. The following directives should go in your server
configuration (httpd.conf) file. The first line tells mod_perl to
force a reload of modules when Apache is restarted. The
<Perl></Perl> section is Perl code to be executed by Apache at server startup. In this case, all does is add the directory containing the handler modules to Perl's library search path. The TopTenTrans.pm file should be located in this directory. The last line instructs mod_perl that the three modules listed should be loaded by the server at startup time.
srm.conf. Two lines need to be added to srm.conf. The first two lines create aliases in the server's document tree to the directories where our Apache::Registry CGI scripts reside (one which will not be password protected, the other which is). The third line
tells the server that the output generated by Embperl files should
be given a MIME content type of text/html.
access.conf. The last configuration file that needs to be modified is access.conf. The first group of lines (in between the
<Files> directives) tells Apache to allow mod_perl to handle
any files which end in .epl. The actual Perl handler which will
be called is the HTML::Embperl::handler() subroutine, defined by Embperl.
The <Location /perl> section arranges for scripts in /usr/local/apache/perl to be run under Apache::Registry. It also specifies several environment variables which should be set in %ENV for the scripts.
The next set of directives sets up the authentication for any URLs
beginning with /protected. The first lines in this section make Apache call Apache::Registry to handle requests. The various
PerlSetVar commands set configuration data for the
AuthenDBI handler, such as the DBI data source and table containing
user/password information, and what field names to use
from that table.
The last variable controls whether AuthenDBI uses the crypt() routine to encrypt the password before comparing it against the value from the database. For development it is easier to leave this turned off to facilitate adding users by hand, but in most cases you should never store the plaintext of passwords. It's just asking for trouble.
The final set of directives set up the TopTenTrans and
Apache::Sandwich modules. The PerlSetVar lines specify the location
of our feedback footer, what database to connect to, where
the tracked documents reside in the filesystem, and what document
to use for the index page.
__END__
PUTTING IT ALL TOGETHER
PerlFreshRestart on
<Perl>
use lib qw(/usr/local/apache/lib);
</Perl>
PerlModule Apache::DBI Apache::AuthenDBI HTML::Embperl
Alias /perl/ /usr/local/apache/perl/
Alias /protected/ /usr/local/apache/protected/
AddType text/html .epl
<Files *.epl>
SetHandler perl-script
PerlHandler HTML::Embperl
</Files>
<Location /perl>
SetHandler perl-script
PerlHandler Apache::Registry
Options ExecCGI
PerlSetEnv TopTenDB tpj
PerlSetEnv TopTenPrefix topten
PerlSetEnv TopTenRoot /home/fletch/topten
</Location>
<Location /protected>
SetHandler perl-script
PerlHandler Apache::Registry
PerlAuthenHandler Apache::AuthenDBI
AuthName My Protected Area
AuthType Basic
PerlSetVar Auth_DBI_data_source dbi:Pg:dbname=tpj
PerlSetVar Auth_DBI_username ap_auth
##
## SELECT pwd_field FROM pwd_table WHERE uid_field=$user
##
PerlSetVar Auth_DBI_pwd_table users
PerlSetVar Auth_DBI_uid_field username
PerlSetVar Auth_DBI_pwd_field password
PerlSetVar Auth_DBI_encrypted off
PerlSetEnv TopTenDB tpj
PerlSetEnv TopTenPrefix topten
PerlSetEnv TopTenRoot /home/fletch/topten
<Limit GET>
require valid-user
</Limit>
</Location>
PerlTransHandler TopTenTrans
<Location /topten>
PerlSetVar FOOTER /topten/rate.html
PerlSetVar TopTenDB tpj
PerlSetVar TopTenPrefix topten
PerlSetVar TopTenRoot /home/fletch/topten
PerlSetVar TopTenIndex /home/fletch/topten/index.epl
</Location>
Mike Fletcher works for Internet Security Systems. He lives in
Atlanta with his wife Cathy, dog Phydeaux, and far too many
computers for the liking of the aforementioned wife (no opinion
has been expressed either way by the dog). Fletch once wrote
several chapters about Java for three editions of Java Unleashed
(ISBN 1-57521-298-6; look for it in fine remainder bins everywhere),
but he has long since repented of this folly and returned
to his dark master, Perl. He can be found at http://www.phydeaux.
org/ and fletch@phydeaux.org.