Open Contributions Descriptor — or how to map your contribution in open source, open data, and open standards
Open Contributions Descriptor — or how to map your contribution in open source, open data, and open standards
Open ecosystems thrive on collaboration. Open source software, open data initiatives, and open standards communities all depend on a complex web of contributors, maintainers, organizations, and users working together across domains and borders.
Yet, despite this openness, one surprisingly difficult question remains:
Who contributes what — and how can others participate?
The Open Contributions Descriptor (OCD) was designed to answer exactly that question.
This post explains the story behind the Open Contributions Descriptor, the problem it aims to solve, and how it helps map contributions across the open ecosystem in a way that is both human readable and machine actionable.
Where the idea started
The Open Contributions Descriptor did not emerge in isolation.
The original inspiration came from Mozilla’s contribute.json initiative: https://github.com/mozilla/contribute.json.
Mozilla introduced the idea that projects could publish a small machine readable file describing how people could contribute. It was a simple but powerful concept: contribution entry points should be discoverable automatically rather than buried inside documentation.
Although the project is now archived, the underlying idea remained compelling:
Contribution information should be structured, portable, and published by the project itself.
The Open Contributions Descriptor expands this original vision beyond onboarding contributors to a single project and generalizes it across:
- open source
- open data
- open standards
- broader open ecosystems
In a way, Open Contributions Descriptor (OCD) can be seen as a natural evolution of that early experiment, extending contribution metadata from project contribution guidance to ecosystem mapping.
The problem: visibility in a fragmented open ecosystem
Open ecosystems are rich but fragmented1.
Today, information about contributions is scattered across many places:
- Git repositories
- README files
- governance documents
- mailing lists
- project websites
- data portals
- standards organizations
- issue trackers
- funding reports
Each project documents participation differently or sometimes not at all.
As a result:
- Contributors struggle to understand how to get involved.
- Organizations cannot easily demonstrate their open contributions.
- Communities lack visibility into dependencies and relationships.
- Researchers and policymakers cannot map the real impact of openness.
- Automated catalogues of open initiatives are difficult to build.
Ironically, while open projects publish code and data transparently, the structure of contributions themselves remains opaque or unknown.
A recurring realization at FOSDEM
Every year, attending FOSDEM is an inspiring experience.
Walking through the corridors, talking to maintainers, and visiting project stands inevitably leads to the same realization:
I constantly discover mature, impactful open source projects I had never encountered online before.
Projects with active communities, real deployments, and years of development somehow remain invisible to traditional discovery mechanisms.
They exist. They are open. They are active.
Yet they are hard to find unless you physically meet the people behind them.
This recurring experience highlights a missing piece in the open ecosystem:
the discovery layer is incomplete.
Search engines index code. Platforms index repositories. Conferences reveal communities. But there is no universal, structured way for projects to declare:
- who they are
- how they operate
- how others can participate
There is a missing key, not to access the code, but to understand the collaboration around it.
Beyond open source: a shared challenge
The challenge is not limited to software.
Across ecosystems we see similar issues:
| Domain | Example Questions |
|---|---|
| Open Source | Who maintains the project? Who funds development? |
| Open Data | Who produces the dataset? Who curates it? |
| Open Standards | Who participates in working groups? Who implements the standard? |
| Research | Which institutions contribute to which initiatives? |
These domains overlap constantly. A single organization may:
- maintain open source tools
- publish open datasets
- contribute to standards bodies
- depend on other open projects
But there is no simple, structured way to describe these relationships consistently.
The hidden structural problem: centralized directories
Another, less visible issue exists in today’s open ecosystem: centralized discovery.
Many catalogues, registries, and directories attempt to index open projects. While useful, they often share a structural limitation:
A single platform or organization becomes the gatekeeper of discovery.
In practice, this means:
- inclusion depends on platform policies
- metadata formats are platform specific
- projects must register manually
- ecosystem visibility depends on maintaining accounts in external systems
- long term sustainability relies on the continued existence of one operator
Even in open ecosystems, discovery frequently depends on a central directory holding the “golden key” to visibility.
This creates several risks:
- single points of failure
- loss of neutrality
- vendor or platform lock in
- incomplete ecosystem representation
- barriers for smaller or independent initiatives
Openness should not depend on a single registry.
The idea: describe contributions as first class metadata
The Open Contributions Descriptor (OCD) introduces a simple idea:
Contributions themselves should be described using an open, structured, machine readable format published directly by the project.
Instead of embedding contribution information informally in documentation, projects publish a descriptor file that answers:
- What is this initiative?
- What type of openness does it represent?
- Who contributes?
- How can others contribute?
- What roles exist?
- How are decisions made?
- Where are the contribution entry points?
The goal is not to replace existing documentation but to standardize discovery and mapping.
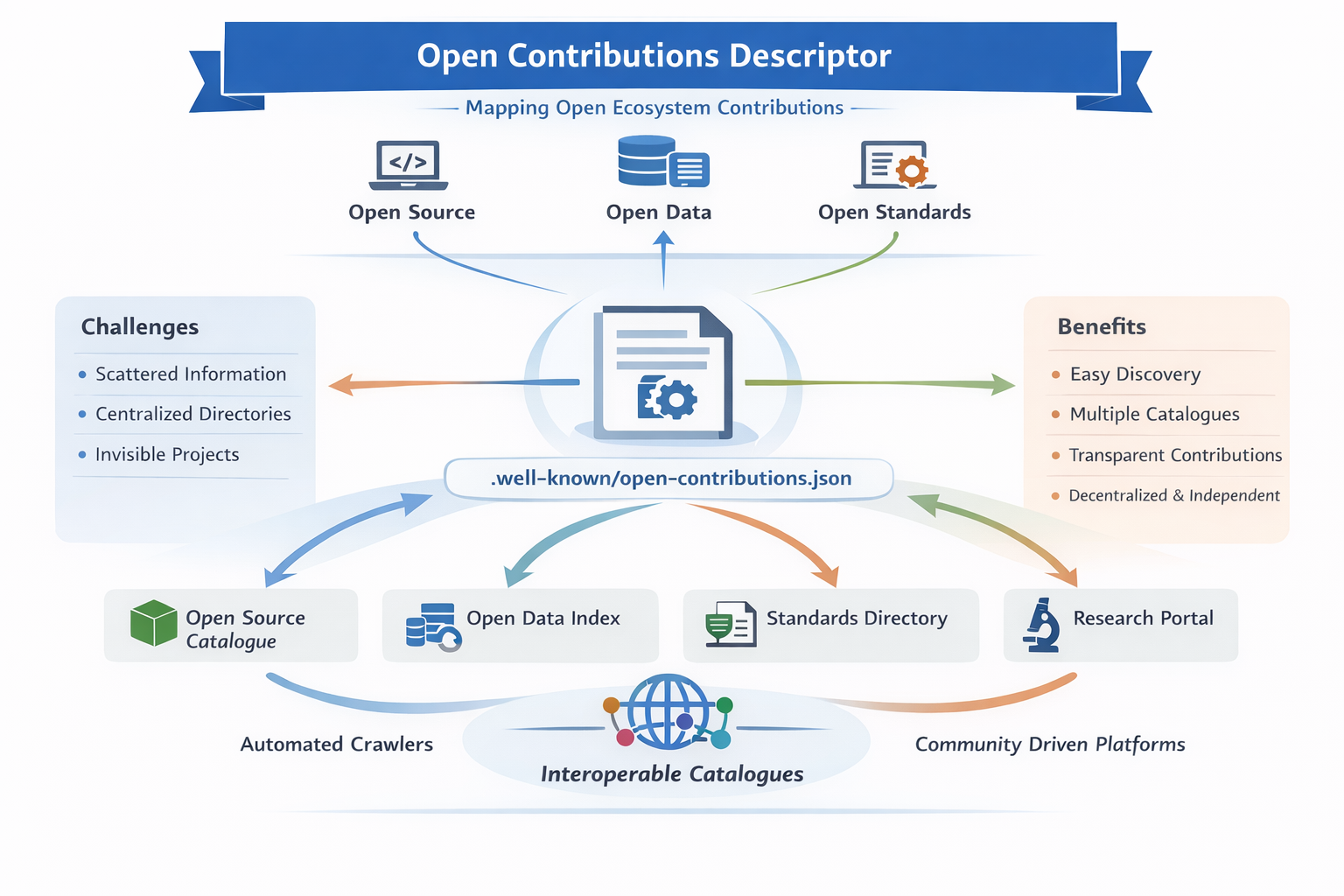
A standardized discovery location
To make automated discovery reliable, the descriptor is published in a predictable location using a well known URI.
The Open Contributions Descriptor (OCD) is stored as a JSON document named:
.well-known/open-contributions.json
This follows the established .well-known convention defined by RFC 8615, which allows services and metadata to be discovered automatically at standardized paths on a domain.
By placing the descriptor at a well known location:
- crawlers know exactly where to look
- projects remain in control of their metadata
- discovery becomes interoperable across platforms
- no registration in external directories is required
To formalize this approach, a registration request for the open-contributions.json well known URI has been submitted to IANA:
https://github.com/protocol-registries/well-known-uris/issues/78
This step is important because it moves the descriptor from an informal convention toward an Internet recognized discovery mechanism, reinforcing long term interoperability and neutrality.
Decentralized discovery by design
A key property of the Open Contributions Descriptor is directory independence.
The descriptor lives with the project or organization itself, not inside a centralized platform.
This changes the discovery model fundamentally:
| Traditional Model | OCD Model |
|---|---|
| Register project in a directory | Publish descriptor in repository |
| Directory owns metadata | Project owns metadata |
| Central authority curates | Anyone can crawl |
| One catalogue | Many interoperable catalogues |
| Platform dependency | Ecosystem independence |
Anyone can build a crawler that discovers descriptors across repositories, websites, or data portals.
There is no central registry required.
Multiple catalogues can coexist:
- research indexes
- public sector inventories
- community driven directories
- organizational dashboards
- academic analysis platforms
This mirrors the architecture of the web itself:
No single organization owns websites. Search engines discover them.
The Open Contributions Descriptor applies the same philosophy to open collaboration.
Design principles
When designing the Open Contributions Descriptor, several principles guided the work.
Domain agnostic openness
The format works across:
- open source
- open data
- open standards
- open research
- open infrastructure
It avoids domain specific assumptions while remaining expressive.
Human readable first
The descriptor is meant to be understandable without tooling.
A contributor should be able to open the file and immediately understand:
- who is involved
- how participation works
- where contributions happen
Machine readable by design
At the same time, the format is structured so that tools can easily:
- parse descriptors
- crawl repositories
- build catalogues
- map ecosystems
- analyze contribution networks
This enables automation without sacrificing clarity.
Lightweight adoption
Projects should not need governance reform to describe themselves.
Many existing directories and metadata formats are designed by committees attempting to normalize the diversity of open ecosystems through rigid governance models. While often well intentioned, they tend to introduce complex requirements, mandatory classifications, approval workflows, or artificial eligibility rules that projects must satisfy before being listed.
In practice, this leads to several problems:
- projects must adapt their governance to fit the directory rather than the reverse
- contributors spend time complying with administrative requirements instead of building software or data
- smaller or unconventional projects are excluded because they do not match predefined models
- innovation is constrained by bureaucratic assumptions about how projects should operate
Over time, such rules unintentionally reduce the usefulness of directories themselves. The more constraints imposed, the less representative the catalogue becomes.
The Open Contributions Descriptor takes the opposite approach.
Instead of committees defining how projects must behave, projects simply describe how they already work.
There is:
- no approval process
- no governance validation
- no mandatory organizational structure
- no centralized interpretation of legitimacy
The descriptor lowers the barrier to participation by adapting to reality rather than attempting to standardize it.
Independence and sovereignty
Perhaps most importantly:
Projects remain sovereign over how they describe themselves.
No platform approval is required. No centralized authority controls visibility. No organization holds the authoritative directory.
Descriptors enable an ecosystem where discovery emerges organically from openly published metadata.
What the Open Contributions Descriptor enables
Mapping the open ecosystem
Imagine being able to automatically discover:
- all projects maintained by a given organization
- datasets linked to specific software
- standards implemented by certain communities
- contribution entry points across ecosystems
Descriptors allow building living maps of openness without centralized ownership.
Easier onboarding for contributors
New contributors often ask:
- Where do I start?
- Who should I contact?
- What skills are needed?
- How do decisions work?
Instead of searching multiple documents, a descriptor provides a structured overview.
Transparency and recognition
Organizations increasingly want to demonstrate their participation in open ecosystems.
The descriptor allows them to clearly expose:
- roles
- responsibilities
- contributions
- collaboration models
This improves recognition without requiring manual reporting or third party platforms.
Machine discoverable catalogues, plural not singular
One of the core objectives is enabling automated catalogues of:
- open source projects
- open datasets
- open standards initiatives
Importantly, there is not one catalogue. Anyone can build one. Competition, diversity, and experimentation become possible because the metadata layer is open and decentralized.
A simple mental model
Think of the Open Contributions Descriptor as:
- package.json for contributions
- robots.txt for openness
- metadata for collaboration
- DNS for open participation
It tells both humans and machines:
“Here is how this open initiative works and how you can participate.”
Example use cases
Open source project
A project publishes an OCD file (MISP project open-contributions.json file) describing:
- maintainers and governance
- contribution guidelines
- communication channels
- funding or supporting organizations
Tools can automatically include it in multiple independent catalogues.
Open data platform
A dataset provider describes:
- data producers
- curators
- update responsibilities
- contribution workflows
- licensing and reuse expectations
Researchers can discover participation opportunities instantly.
Open standards working group
A standards initiative describes:
- working groups
- participation model
- implementation communities
- decision processes
Implementers gain clarity without navigating institutional silos.
Why a standard matters
Without a shared descriptor:
- every ecosystem reinvents metadata
- automation becomes brittle
- discovery remains centralized or manual
A common format enables interoperability between communities that historically evolved separately but now collaborate closely.
The Open Contributions Descriptor aims to become a common language for openness without central control.
Open by design
The specification itself is openly developed and available here:
https://github.com/ossbase-org/Open-Contributions-Descriptor
The goal is community driven evolution:
- feedback from open source maintainers
- adoption by open data platforms
- experimentation by standards bodies
- tooling built by ecosystem builders
What comes next
The real value of the Open Contributions Descriptor will emerge through adoption and tooling, including:
- decentralized ecosystem crawlers
- contribution dashboards
- organizational impact mapping
- research analysis
- federated discovery platforms
We envision a future where understanding the open ecosystem becomes as easy as querying a search engine, powered by structured contribution metadata published at the source.
Conclusion
Open ecosystems depend on collaboration, but collaboration itself is still poorly described and too often centrally indexed.
The Open Contributions Descriptor is a small but important step toward making openness discoverable, understandable, decentralized, and measurable.
By standardizing how contributions are described, we can:
- lower barriers to participation
- increase transparency
- preserve ecosystem independence
- avoid centralized gatekeeping
- recognize contributors
- map the global landscape of open collaboration
If open source made code visible, and open data made information visible, the next step is clear:
Make contributions visible without giving anyone the golden key.
Contributions, feedback, and experimentation are welcome because describing openness should itself be open.
- Git repository of the Open Contributions Descriptor: https://github.com/ossbase-org/Open-Contributions-Descriptor
- Online tool to browse or create/edit Open Contributions Descriptor file: https://ossbase-org.github.io/ocd-viewer/app/home.html - Git repository https://github.com/ossbase-org/ocd-viewer
- GitHub organisation generator to Open Contribution Descriptor format: https://github.com/ossbase-org/Open-Contributions-Descriptor/blob/main/bin/github-to-ocd.py
- Discourse topic about OCD format.
- A sample OCD file for the MISP project.
-
The term fragmented is often perceived negatively, suggesting disorder or inefficiency. In open ecosystems, however, fragmentation is largely a strength. It reflects diversity, independence, resilience, and experimentation across communities rather than centralized control. The challenge is therefore not to eliminate fragmentation, but to make it discoverable and understandable without reducing its autonomy. ↩