| Resources | |
| Link Grammar Parser 4.1...................................http://www.link.cs.cmu.edu Lingua::LinkParser 1.01....................................................................CPAN |
|
Regular expressions are one of the triumphs of computer science. While often intimidating to beginning programmers, the ability to capture complex patterns of text in succinct representations gives developers one of the most powerful tools at their disposal. Perl's pattern matching abilities are among the most advanced of any language, and certainly rank among those features which have served to make it one of the most popular languages ever created.
However, regexes can't do everything. When the patterns in your data are complex, even Perl's regular expressions fall short. Natural languages, like English, aren't amenable to easy pattern matching: if you want to find sentences that express a particular sentiment, you need to first understand the grammar of the sentence, and regular expressions aren't sufficient unless you throw a little intelligence into the mix. In this article, I'll show how that can be done.
We will make it possible to write code like this:
# create an array of everything cool
while ($sentence =~ /\G($something_that_rocks)/g) {
push (@stuff_that_rocks, $1);
}
Our notion of "what's cool" can depend not just on simple character patterns, but upon the words in a sentence, and in particular their role in the sentence and relationships to one another. In brief, this article explores the application of regular expressions to grammar. Note that I am not suggesting another syntax for regular expressions. From a Perl hacker's perspective, what I demonstrate here is an interesting application of Perl's overloading ability, and its usefulness when applied to a domain that's tough to parse: natural language.
Before explaining the program, we'll explore the intelligence that we'll use to parse natural language: the Link Grammar.
Many approaches to NLP (Natural Language Processing) have been pursued in the past few decades, but few are as popular as the Link Grammar parser,(Drs. Sleator and Lafferty hail from the computer science department of Carnegie Mellon University, and Dr. Temperley from the music department at Eastman. I wanted to go to Eastman. It didn't work out.) by Drs. Daniel Sleator, Davy Temperley, and John Lafferty. Rather than examine the basic context of a word within a sentence, the Link Parser is based on a model that words within a text form "links" with one another.
These links are used not only to identify parts of speech (nouns, verbs, and so on), but also to describe in detail the function of that word within the sentence. It's one thing to know that a phrase consists of two adjectives and two nouns -- but what you really want to know is which adjective modifies which noun. The Link Grammar does that for you.
The Link Grammar is based on a characteristic that its creators call planarity. Planarity describes a phenomenon present in most natural languages, which is that if you draw arcs between related words in a sentence (for instance, between an adjective and the noun it modifies), your sentence is ungrammatical if arcs cross one another, and grammatical if they don't. This is an oversimplification, but it'll serve for our purposes.
In Link Grammar vernacular, a linkage is a single successful parse of a sentence: a set of links in which none of the connecting arcs cross. A sample parse of the sentence, A camel is a horse designed by a committee is depicted in Figure 1.
Figure 1. A sample parse, with links.
|
The primary parts of speech are labeled with .n and .v to indicate that these words are nouns and verbs, respectively. The labels of the links between words indicate the type of link. For example, the J connector in this sentence indicates a connection between prepositions and their objects; in this case, the verb designed is connected to by a committee, identifying a prepositional phrase. The sidebar "A Few Link Grammar Connectors" briefly summarizes the links used above and elsewhere in this article.
The Link Parser 4.0 provides 107 primary types of links (indicated by the uppercase letters), with many additional subtypes further detailing the relationship of words (indicated by the lowercase characters). While the accuracy of the parser is remarkable, it is tailored to newspaper-style grammar, and will fail with more conversational statements.
The inner workings of the parser are fairly complex, but they use principles which might be familiar. A link grammar considers a sentence to be proper if it satisfies three conditions:
1. Planarity: The link arcs above words do not cross.
2. Connectivity: The links connect all of the words together.
3. Satisfaction: Individual linking requirements of each word are satisfied.
The parser uses a dictionary that contains the linking requirements of each word. For example, the words the, chased, dog, and cat are shown below with their linking requirements. The D within the box above the indicates that another word must connect with D to the right of the in order for the link requirements to be satisfied for that word.
Figure 2. Some linking requirements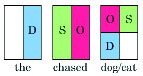
For these words to form a sentence, the parser must find them in an order which satisfies the above three requirements. When a word has more than one row of connectors, only one side (left or right) of each row may be connected (e.g. cat has a row D and a row O/S, so D must be connected along with either O or S). When only one row exists on a single level (e.g. cat has D), one connector must be linked. The meaning of each link used here is indicated above. Thus, the following arrangement is correct: The cat chased the dog.
The unused connectors are grayed out in this example. Since our second the connects to dog as a determiner, chased actually spans the length, connecting to dog. You can mentally shuffle these words to see that cat and dog could be swapped, and likely would be if our program had any semantic knowledge. Moving other words around, however, will break the link criterion and deem the parse ungrammatical.
Figure 3. Linking requirements and inferred links.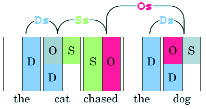
All of these requirements are stored in the Link Parser's dictionary files. The files use a "link dictionary language" to list the requirements for each word, and are themselves an interesting study in pattern representation. A highly optimized custom algorithm processes the data in these files, analyzing the possible links. This algorithm is yet another fascinating study in and of itself.(For those interested, the algorithm is similar to the dynamic algorithm for triangulation of a convex polygon, and has running time of O(N3). The general theory, optimizations, and formalisms are all detailed in the researchers� papers. Frankly, it�s remarkable that it runs as fast as it does given the computation required.)
Because the researchers at CMU had the generosity and intelligence to make their project research open to developers like us, we can examine the ingenuity of their methods. We can use and modify their well-conceived API. We can extend and combine the functionality of their system with that of other language processing technologies. And, of course, Perl makes it all possible, practical, and inevitable.
The Link Grammar parser itself is a complex piece of software implementing a complex theory of language. The Perl module Lingua::LinkParser directly embeds the parser API, providing an object-oriented interface that you can use from your Perl programs. Objects may be created to represent sentences, linkages, links, individual words, and the parser itself. As an example, consider the following code:
use Lingua::LinkParser; use strict; my $parser = new Lingua::LinkParser; # create the parser my $text = "Moses supposes his toses are roses."; my $sentence = $parser->create_sentence($text); # parse the sentence my $linkage = $sentence->linkage(1); # use the first linkage print $parser->get_diagram($linkage); # print it outThis code will output:
+-------------------------Xp------------------------+
| +------Ce------+ |
+---Wd--+---Ss---+ +--Dmc--+--Spx--+--Opt-+ |
| | | | | | | |
LEFT-WALL Moses supposes.v his toses[!].n are.v roses.n .
Without delving into all the details, this diagram reveals some interesting things about the parser. First, supposes and are have v labels, indicating that they're verbs. The word roses is labeled n for noun, as is toses. The [!] tag next to toses indicates that the parser isn't familiar with this word, which usually means that it isn't a word at all. So even with a word it's never seen before, the Link Grammar can identify the part of speech
.The diagrams help us understand the link grammar, but to use the information within a program requires access to the links themselves. Continuing with the program above, we will extract from the $linkage object an array of $word objects. These will spring into existence, along with a links() method to return an array of $link objects. Well, just watch:
my @words = $linkage->words;
foreach my $word (@words) {
print "\"", $word->text, "\"\n";
foreach my $link ($word->links) {
print " link type '", $link->linklabel,
"' to word '", $link->linkword, "'\n";
}
}
An excerpt from the output:
"Moses"
link type 'Wd' to word '0:LEFT-WALL'
link type 'Ss' to word '2:supposes.v'
"supposes.v"
link type 'Ss' to word '1:Moses'
link type 'Ce' to word '4:toses[!]'
"his"
link type 'Dmc' to word '4:toses[!]'
"toses[!]"
link type 'Ce' to word '2:supposes.v'
link type 'Dmc' to word '3:his'
link type 'Spx' to word '5:are.v'
Knowing the part of speech and linkages of each word allows us to use grammatical constructs in a program. Let's write one.
Returning to our original problem, how can we expand our pattern matches to handle grammatical constructs rather than simple combinations of metacharacters? We have two tools: the Link Parser just described, and Perl's overloading, which allows us to redefine how Perl's operators operate. In particular, we're going to redefine how Perl processes strings.
Normally, operator overloading is used to extend the definition of common operators, like +, so that you can say things like $madness = $vanhalen_mp3 + $vivaldi_mp3 and overlay two MP3s as a result.
For our purposes, we overload double-quote processing in the Lingua::LinkParser::Linkage package so that when you print a linkage object, it displays a linkage diagram. Furthermore, to pattern match the data, we need a format that is more easily parsed, but still just a single string. Something like the following would be nice, listing the words with their links on each side in an ordered, linear format:
(Wd:0:LEFT-WALL "Moses" Ss:2:supposes.v) \ (Ss:1:Moses "supposes.v" Ce:4:toses[!]) \ ( "his" Dmc:4:toses[!]) \ (Ce:2:supposes Dmc:3:his "toses[!]" Spx:5:are.v) \
We can get this type of output with print $linkage by modifying the file Linkage/Linkage.pm and changing the overload behavior. Figure 3 shows the change, illustrating the results of new_as_string() method rather than the as_string() method. Now, printing the object $linkage from the previous examples will output the text shown above, in one long string.
Finally, we can pattern match that text to find what we're looking for. In this case, we're going to look for the Ss link from Moses, indicating a connector to the verb for our subject:
$Moses = '"Moses" ';
$does_something = 'Ss:\d+:(\w+)\.v';
$action_by_moses = "$Moses$does_something";
if ($linkage =~ /$action_by_moses/o) {
print "What does Moses do? He $1.\n";
}
This prints What does Moses do? He supposes. We could take the idea further by overloading the right side of our regular expressions and getting them to return word objects, but we won't.
Peeking under the hood, here's how the overloading is implemented.
use overload q("") => "new_as_string";
sub new_as_string {
my $linkage = shift;
my $return = '';
my $i = 0;
foreach my $word ($linkage->words) {
my ($before,$after) = '';
foreach my $link ($word->links) {
my $position = $link->linkposition;
my $text = $link->linkword;
my $type = $link->linklabel;
if ($position < $i) {
$before .= "$type:$position:$text ";
} elsif ($position > $i) {
$after.= "$type:$position:$text ";
}
}
$return .= "(" . $before . " \"" . $word->text . "\" " .
$after . ")" ;
$i++;
}
"(" . $return . ")";
}
The "Operating System Sucks-Rules-O-Meter" by Don Marti (http://srom.zgp.org/) inspired Jon Orwant's "What Languages Suck" program, later adopted by Steve Lidie (http://www.lehigh.edu/~sol0/rules.html). It blesses all of our lives by counting the web sites that state visual basic sucks, perl rules, and so on. The numbers are then plotted on a graph, giving us a crude and comical sampling of the net's public opinions about languages.
What if someone wanted to perform a search that would produce lists of anything that people think sucks or stinks, and rules or rocks? A quick search for rocks on Altavista reveals plenty of geology links, and news headlines like Senate confrontation rocks Capitol Hill. We just want those phrases that state that something rocks, so we need to analyze the grammar of the search results.
First, we need to determine the syntax for the data we want to collect. We use the first script listed in this article to experiment, or we could think through the grammar a bit: the rock we are looking for is not only a verb, but a verb without an object. This would serve to differentiate our meaning from the two others mentioned above.
+------------Xp------------+
+--Wd--+--Ss-+---Op---+ |
| | | | |
LEFT-WALL he studies.v rocks.n .
Note that this diagram displaying only one linkage, but there might be many. In the above output from our script, He studies rocks has been parsed and labeled. The subject of the sentence (he) is shown with an Ss label, connecting a singular noun to the singular verb form (studies). This will be the connector we are looking for in our rocks phrase, but here it occurs with the wrong verb. It has identified rocks as a noun here, and linked rocks to studies with an Op connector. The Link Parser documentation tells us that O connects transitive verbs to direct or indirect objects, and so the p subscript reflects the plurality of the object, rocks.
+--------------------Xp-------------------+
+-------Wd------+ +-----Os----+ |
| +---Ds---+----Ss---+ +--Ds-+ |
| | | | | | |
LEFT-WALL the earthquake.n rocks.v the city.n .
This example recognizes the verb usage of rocks as an action being performed by earthquake. Do earthquakes rock? Not in the sense we are looking for, since rocks has a connector to the city as an singular object (indicated by Os). Objects suck, at least for our purposes. Let's try another.
+-----------------------Xp----------------------+
+----------------Wd---------------+ |
| +------------D*u-----------+ |
| | +----------AN---------+ |
| | | +-----AN-----+---Ss---+ |
| | | | | | |
LEFT-WALL the Perl programming.n language.n rocks.v !
Again, rocks here is correctly recognized as a verb, and again, it is connected via Ss to a subject. But this time rocks is not a transitive verb, since it has no objects. The grammar of this sentence would satisfy our requirements for rocks. So now that we have the correct usage, how do we extract the subject? We don't want to use just language to compile our statistics � we want Perl programming language. To find a solution, take note of the AN connectors that span these words. The Link Grammar reference identifies this link type as connecting modifiers to nouns. In the case above, both Perl and programming are modifiers for language. We can plan at the outset to always look for modifier links to our subject, and include them in the data we extract from the sentence. And there's more that we'll need, as you'll see.
Once we have determined the general grammatical elements for which to search, we can write a program that finds those elements in a given text. Since we overloaded this object's string handling to return the linkage information in a linear format, we can now formulate a regular expression that represents the grammar we want to match.
$what_rocks = 'S[s|p]' . # singular and plural subject
'(?:[\w\*]{1,3})*' . # any optional subscripts
':(\d+):' . # number of the word
'(\w+(?:\.\w)*)';
# and save the word itself
$other_stuff = '[^\)]+'; # junk, within the parenthesis
$rocks = '"(rocks*)\.v"'; # singular and plural verbs
$pattern = "$what_rocks $other_stuff $rocks";
if ( $linkage =~ /$pattern/mx ) {
print "$2 rocks.\n";
}
Our $what_rocks portion of this pattern looks for an S link from rocks, and stores the word itself in $2, with optional tags like .n after the word. (We will use the stored word number in a moment.) This regular expression works, but it works for every verb sense of rocks that has a subject, including the earthquake rocks the city. We need to limit our pattern to match only those usages of rocks that have no objects at all. Here, we add a pattern after $rocks to be sure that no O connectors exist for rocks:
# match anything BUT an 'O' link, to the end parenthesis
$no_objects = '[^(?:O.{1,3}:\d+:\w+(?:\.\w)*)]*\)';
$pattern = "$what_rocks $other_stuff $rocks $no_objects";
With these changes, the pattern only matches the verb rocks when it has no objects. But one problem remains: when we use our regex with proper nouns like Pat Metheny rocks or noun modifiers like the Perl programming language rocks, we get only one word as the thing that rocks. Our pattern is getting a bit messy, so rather than add to it, we'll add a statement within the if block to scoop up the rest of the names. Proper nouns are strung together with G connectors, and noun modifiers with AN.
if ( $linkage =~ /$pattern/mx ) {
$wordobj = $linkage->word($1); # the stored word number
$wordtxt = $2;
$verb = $3;
@wordlist = ();
foreach $link ($wordobj->links) { # process array of links
if ($link->linklabel =~ /^G|AN/) {
$wordlist[$link->linkposition] = $link->linkword;
}
}
print join (" ", @wordlist, $wordtxt), " $verb\n";
}
Note how although we are looking for matches in $linkage, we are using a method, $linkage->word, in the next line. (Seeing objects used in both scalar and dereferenced context may look confusing at first.) Also, we store the words in the @wordlist array to maintain the order of these words. When run with sentences provided by the user, this block of code prints the following:
Enter a sentence> He studies rocks.
Enter a sentence> The earthquake rocks the city.
Enter a sentence> The Perl programming language rocks.
-> Perl programming.n language.n rocks
Enter a sentence> Linux rocks!
-> Linux rocks
Enter a sentence> He was telling me why he thinks that San Francisco rocks.
-> San Francisco rocks
The final listing for this program is in Listing 1, and includes additional modifications to permit possessive pronoun inclusions, grouping of possessive proper nouns, conjunctions, past tense, and attributive adjectives. A demonstration is shown below.
Enter a sentence> Roland Orzabal's music rocks.
-> Roland Orzabal 's.p music.n rocks
Enter a sentence> Strangelove rolls, rumbles, and rocks.
-> Strangelove rocks
Enter a sentence> The Perl conference rocked!
-> Perl Conference rocked
Enter a sentence> The shogimogu pyonuki dancers rock!!!
-> shogimogu[?].a pyonuki[?].a dancers.n rock
(Thanks to my wife for pointing out all of the grammar that would not work with my first attempts.)
Although the parser has no clue what the shogimogu and pyonuki mean (nothing at all, as it happens), it is still able to identify these as attributive adjectives. Anyone who has ever used another grammar-based parser will appreciate this feat.
We could compile literally thousands of patterns to match various grammatical phenomena, store them in constants within a module, and end up with a direct regex interface for analyzing grammar. That will be the Lingua::LinkParser::Regex module, currently in progress.
Using this framework, the What languages suck? application could be extended to retrieve web links to the pages resulting from a search engine query for rocks, rules, sucks, and so on. The text of each page could then be split into sentences, parsed with the code shown here to find specific word usages, and graphing the results. I won't outline how such a utility would be developed; the documentation for the LWP and GD modules tells you all you need to know. If anybody does write it, I suggest having multiple exclamation points count progressively against the rocks rating of the subject, rather than for it. We need to discourage that. Thank you.
Certainly the possible applications of this type of "regex grammar" extend far beyond the toy application I've shown here. Smart search engines, document categorizers, and automated response systems all can make use of similar front ends to natural language.
The Link Grammar can hardly be fully described in this article, and I encourage anyone interested to delve further into the research in this field. There is lots of room here for continued innovation, and the parser itself has much more to offer than what's been described here.
_ _END_ _Link Grammar web site, http://bobo.link.cs.cmu.edu/ index.html/.
Daniel Sleator and Davy Temperley, Parsing English with a Link Grammar, Third International Work-shop on Parsing Technologies, August 1993.
Daniel Sleator and Davy Temperley, Parsing English with a Link Grammar, Carnegie Mellon University Computer Science technical report CMU-CS-91-196, October 1991.
Dennis Grinberg, John Lafferty, and Daniel Sleator, A robust parsing algorithm for link grammars, Carnegie Mellon University Computer Science technical report CMU-CS-95-125.